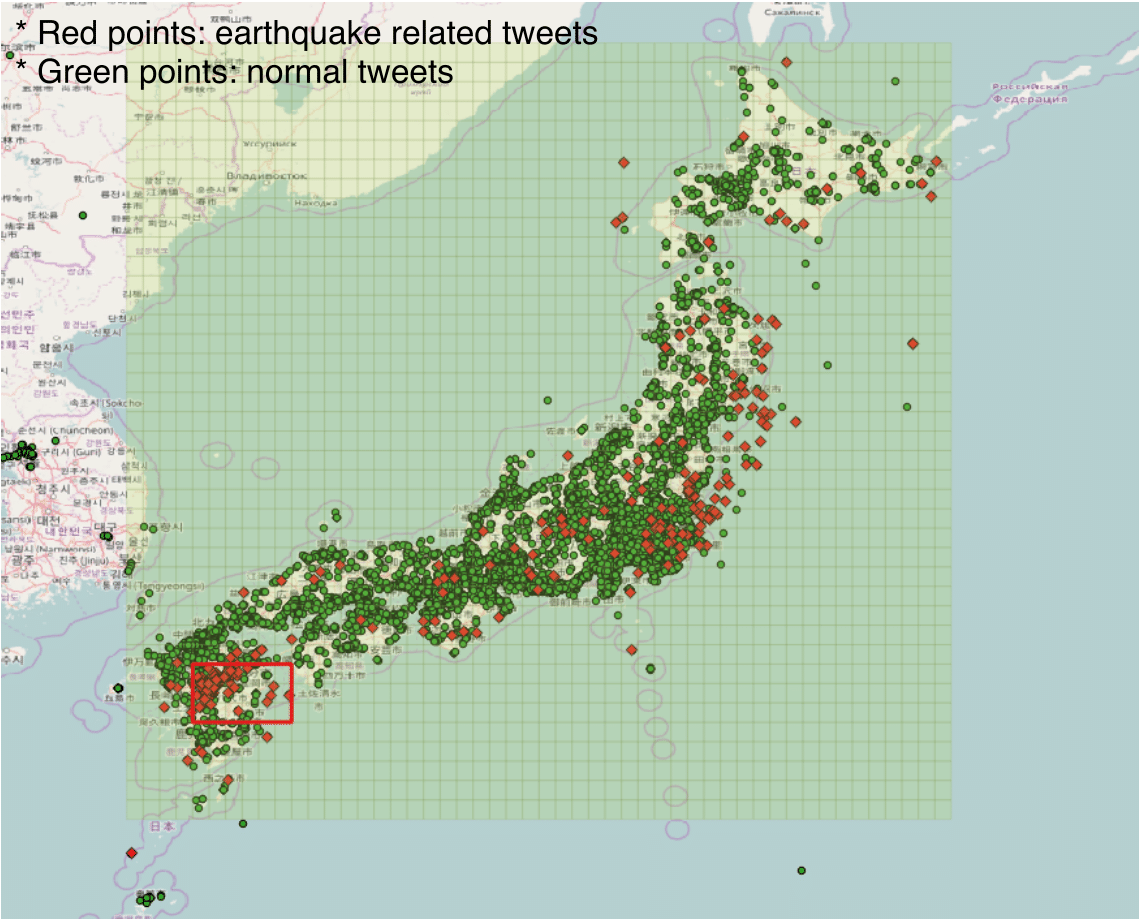
Fig. 1: Fig. 1: (Left) Office building - Illustrative IoT Layout. (Right) Hotspot of Earthquake related Tweets after Kumamoto Earthquake (April-May, 2016).
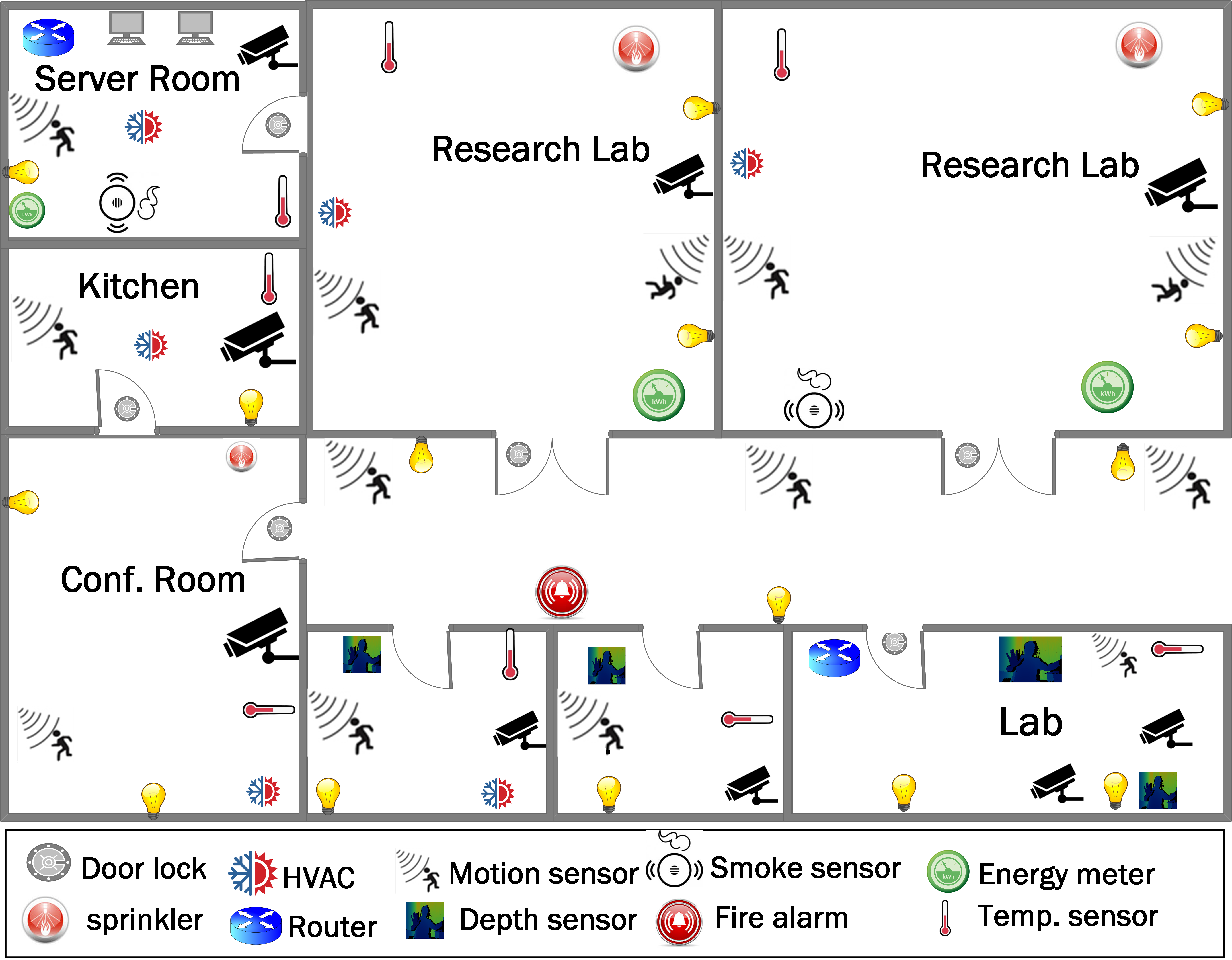
The increasing proliferation of the Internet of Things (IoT) devices and systems result in large amounts of highly heterogeneous data to be collected. Although at least some of the collected sensor data is often consumed by the real-time decision making and control of the IoT system, that is not the only use of such data. Invariably, the collected data is stored, perhaps in some filtered or downselected fashion, so that it can be used for a variety of lower-frequency operations. It is expected that in a smart city environment with numerous IoT deployments, the volume of such data can become enormous. Therefore, mechanisms for lossy data compression that provide a trade-off between compression ratio and data usefulness for offline statistical analysis becomes necessary. In this project, we study several simple pattern mining based compression strategies for multi-attribute IoT data streams, and evaluate the compressibility of the method vs. the level of similarity between original and compressed time series in the context of the home energy management system (shown in Fig. 1).
We have also collected a number of disaster related twitter data from real disaster scenarios and alanyzed them for different practical applications. For example, "spatial clustering" of the events scattered over a geographical region has many important applications, including the assessment of needs of the people affected by a disaster. In this project we consider spatial clustering of social media data (e.g., tweets) generated by smart phones in the disaster region. For example the following information was used during and after the Great East Japan Earthquake (shown in Fig. 1): (1) The tag '#j_j_helpme' was used on Twitter following the earthquake and tsunami as a way for emergency personnel to rapidly identify people in need of rescue; (2) Google tweeted a link on Twitter to its Google Person Finder tool, which enables people to search for missing family members. Our goal in this context is to find high density areas within the affected area with abundance of messages concerning specific needs that we call simply as "situations". Unfortunately, a direct spatial clustering is not only unstable or unreliable in the presence of mobility or changing conditions but also fails to recognize the fact that the situation expressed by a tweet remains valid for some time beyond the time of its emission. We address this by associating a decay function with each information content and define an incremental spatial clustering algorithm (ISCA) based on the decay model.
In this context we have also developed a situational awareness service, named "StayTuned" that collects information from social media, extracts relevant messages, and broadcasts them to the sub- scribers through wireless emergency alert system. StayTuned uses automated filtering and summarization of messages and up-dates subscribers with real-time situational summaries. Extensive experiments were conducted using twitter data collected during the Sandy hurricane to evaluate performance of the automated message extraction.
Related Publications: