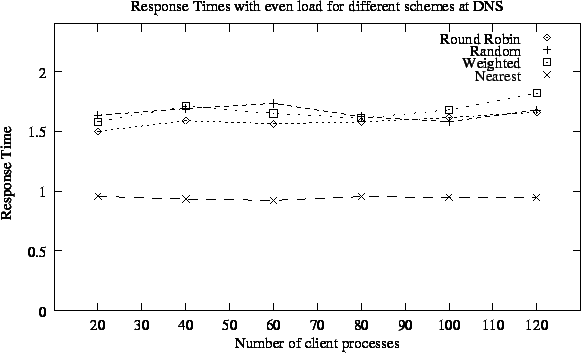
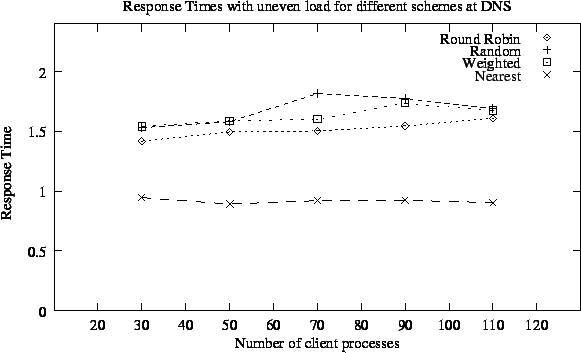
We have plotted average response time with different load distribution for different policies in Figure 5.5 and Figure 5.6. As the plots show that under the network conditions assumed by us, our RTT based nearest cluster selection approach outperformed other approaches by a good margin. While other approaches have average response times in range of 1.5 seconds to 1.8 seconds, our approach gave average response time in range of 0.92 second to 0.96 seconds. Thus our results verify that if the links connecting different geographical regions have much higher delay and higher packet losses as compared to links within same geographical region (which is usually the case), we can provide better response time to clients by taking into account the network conditions by using round trip time.
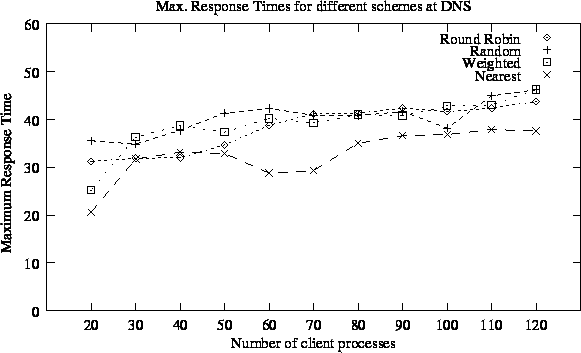
We have also plotted maximum response time for any connection under different policies, we once again see that our policy performs better. These results would be much better if clients in other geographical regions had lesser delays and packet losses with any of nearby cluster (we had set up higher delays and high packet losses with every cluster). The results are plotted in Figure 5.7.
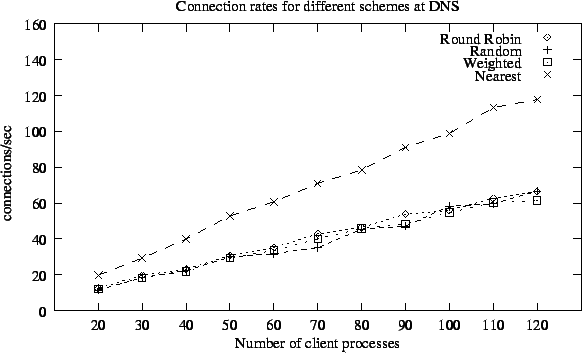
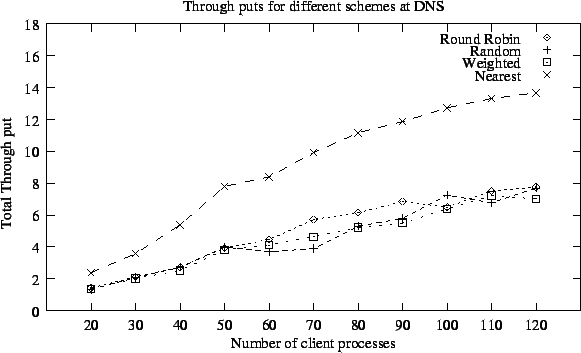
Other two plots, average connection rate (number of connections/sec) and server throughput are shown in Figure 5.8 and Figure 5.9 respectively. The large difference in connection rate and hence higher throughput is attributed to aggressive sequential connection policy used by Webstone software, which tries to send connection requests as fast as possible if earlier requests are serviced quickly. Almost similar response time for varying number of client requests also shows that in our test bed requests were distributed properly by all policies in most cases and servers were not loaded enough.
In our proposed system, more servers and clusters can be added easily without bringing down the system. Our system is also fault tolerant since if any server in the cluster goes down, front node does not receive system state information and does not send any new requests to that server. However, all connections already established with that server are not gracefully handled. Similarly, DNS did not resolve IP address of cluster that went down, clients who were unable to connect to resolved cluster, try other cluster IP addresses and connect to other clusters. This time too, clients having already established connection with that cluster get errors but no new connection afterwards is scheduled to cluster until it comes up again.
In short, we can conclude that our architecture scaled well and our proposed nearest cluster selection approach should give better results if network conditions for access within same geographical region are much better than network conditions while accessing clusters in other geographical regions.