BGP Instability
The Internet is made up from large number of administrative control blocks, called AS i.e. Autonomous Systems. Most autonomous systems exchange routing information through the BGP i.e. the Border Gateway Protocol. BGP as the inter domain routing protocol can cause instability in the network, which is yet to converge. The BGP instability is considered to be bad, becasue of the reasons as explained below.
Why BGP Instability is BAD?
- Caching is not effective :
Most of the routers today, in the core of the Internet, are based on "Route Caching" Architecture. The routers that are based upon such architecture maintain the routing table cache of the destination and next-hop lookups. As long as router's interface card finds a cache entry for an incoming packets destination addresses, the packet is switched on the cached address path, independent of the router's CPU. However under severe routing instability, the cache undergoes frequent updates, and defeats the purpose of caching architecture, where by a large number of cashe misses ensue, resulting in increased load on the router's CPU, increased switching latency and the loss of packets. - Route "Flap Storm" :
Another phenomena that ensues as a result of BGP routing instability is, what is known as Route Flap Storm. These phenomena is usually fired by a router which fails under heavy routing instability. Frequently enough, the overloaded routers are unable to maintain the required interval of Keep-Alive messages to the neighbouring routers. The failure to maintain the Keep-Alive transmissions causes other routers to mark the overloaded router as unreachable. Due to this the peer routers choose alternate paths for destinations previously reachable through the overloaded router, falsely marked as "down", and transmits updates reflecting the change in the topology to each of the peers. These frequently causing fallacies, may lead to yet more routers to failure, and initiating the route flap stroms. - Large state dump :
When such "Down"routers, as explained above, tries to attempt to re-initiate the BGP peering session with each of its peer routers,it generates large state dump transmissions, which furthers the problem of instability, and aids route flap storm to permeate the network.
- Caching is not effective :
Ways to Reduce Instability
- Address aggregation :
One of the solutions proposed to deal with the routing instability is use of route address aggregation. Aggregation combines a number of smaller IP address prefixes into a single, less specific route address. Since this technique reduces the number of effective networks visible to the core of the Internet, the BGP updates become less frequent, and hence helps stabilise or say, converge the network. - Route servers :
The route servers acts as agents between the peering BGP routers. Each router at an exchange point normally has to exchange the routing information with each of the peering BGP router. This is of the order O(N**2) bilateral peering sessions. The route server comes in way to help reduce this computationally complex peering from individual routers onto single centralized Route Server. This server maintains peering sessions with each of the exchange point routers and performs the routing table policy computations on the behalf of each of the client peer. Hence each client peer needd to maintain a single peering session with the router server, hence reducing the number of the peering sessions to O(N). - Route dampening
Another technique which is usually deployed is Route Dampening. The algorithms used for route dampening, in the routers, refuses to beleive updates about routes that exceeds certain parameters of instability, say e.g. number of updates in an hour. A router using route dampening algorithms, will not procees additional updates for the dampened routes, untill a preset period of time.
However all of the above methods do have certain limitations or drawbacks. Many end-sites choose to obtain reduntant connectivity to the Internet, via multiple ISPs. This, Multi-Homing requires that each of the core Internet router maintain a more specific, or longer, prefix in addition to any less specific aggregate address block prefixes covering multi-homed site. The problem with the route servers is that they cannot help limit the flood of instability informtion. Route dampening methods may introduce the artificial connectivity problems, as "legitimate" announcements about a new network may be delayed due to earlier dampened instability.
- Address aggregation :
Classifying Updates
The BGP updates can be classified according to the (prefix, peer) tuple. The paper has discussed five types of updates, as described below.
- WADiff :
A route is explicitly withdrawn, as it becomes unreachable, and it is later replaced with an alternative route to the same destination. The alternative route differs in its ASPATH or nexthop attribute information. This is classified as forwarding instability. - AADiff :
A route is implicitly withdrawn, and replaced by an alternate route as the original route becomes unreachable, or a preferred alternative path becomes available. This too, has been classified as forwarding instability. - WADup :
A route is explicitly withdrawn, and then reannounced as reachable. This may reflect temporary topological (link or router) failure, or it may represent pathological oscillation. This may be either considered as forwarding instability or pathological instability. - AADup :
A route is implicitly withdrawn, and replaced with a duplicate of the original route, i.e. to say that the subsequent route announced does not differ in the nexthop or ASPATH attribute. This may reflect pathological behaviour as a router should only send a BGP update for a change in topology or policy. However this may also be due to policy fluctuation. - WWDup :
The repeated transmission of BGP withdrawls for a prefix that is currently unreachable. This is a pathological behaviour.
- WADiff :
Results
- No. of Updates = 10 x no. of expected updates, in the path vector algorithm.
- The BGP instability is dominated by the pathological updates.
- The BGP instability shows up a form of periodicity of around 30-60 seconds.
- There is correlation between the network usage and the number of updates.
- Pathological updates dominated by small ISPs, but no such pattern in instability.
- Summary : There is a significant level of Internet instability
- No. of Updates = 10 x no. of expected updates, in the path vector algorithm.
* * * * * |
Packet Switching and Congestion Control
Congestion
When too many packets are present in a network (or a part thereof), the performance of the network, in terms of total throughput, average queued delay per packet, no. of packets lost, etc degrades. This situation is called congestion. It is simply overload that the network cannot handle. When the number of packets dumed into the network is within it's carrying capacity, they are all delivered (except for a few that are afflicted with transmission errors), and the number of packets delivered successfully is proportional to the number sent. However, as the traffic increases too far, the routers are no longer able to cope, and they begin to loose packets. At very high traffic, performance collapses completely, and almost no packets arew delivered. Congestion can be brought about by several factors.If all of a sudden, stream of packets begin arriving on many input lines, and all need same output line, a queue will build up. Eventually the buffer associated will get exhuasted, and the lose of packets will ensue. Slow processors can also cause congestion. If the routers' CPU are slow at performing bookkeeping tasks required of them, queues can build up, even though there is excess line capacity. Similarily, low bandwidth lines can also cause congestion. Congestion control was once considered to be a problem of avoiding buffer exhaustion. However adding memory may help up to a point, but Nagle[87] discovered that if routers have an infinite amount of memory, congestion gets worse.
Congestion & Infinite Storage
Nagle[1987], in his paper has pointed out a very interesting implication of the infinite buffers for storage of packets. In the DoD IP protocol, packets have a time-to-live field, which is the number of seconds remaining until the packet must be discarded as uninteresting. As the packet travels through the network, this field is decremented, if it becomes zero, the packet must be discarded. Now we see what happens in case of infinite buffer. The figure below is in the center of the dicussion.
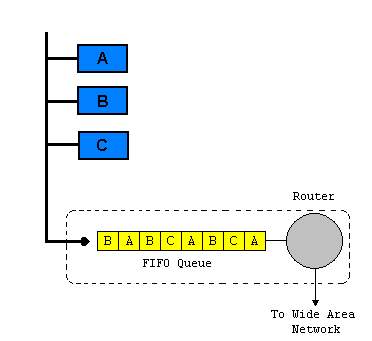
Suppose that the host A by itself generates all the traffic necessary to saturate the output links. Now since the packets have TTL(Time to Live) field, eventually the packets that starts getting queued up in the buffer, will have their TTL already reached to zero. In such cases the packet must be discarded. Those packets for which, the TTL remains above zero by a nominal margin, gets routed, but are again queued up in the next router, and eventually are discarded from next router. Hence eventually all tha packets in the buffer will have TTL already elapsed past it's lifetime, and thus all the packets will get discarded.
Congestion Control & Avoidance
In his paper, Nagel has pointed out certain key factors, that are necessary to avoid and/or control the congestion in the network. One of the key points is that transport protocols used in datagram systems should behave in such a way as to not overload the network i.e. the transport protocol must react to the congestion by reducing the sending rate. However there in no motivation for a host to be well behaved.to packet-switched networks. Each host can normally obtain more network bandwidth by transmitting more packets per unit time since the first-in, first-out strategy gives the most resources to the sender of the most packets. But collectively, as the hosts overload the network, total throughput drops.
Possible solutions :
Solutions to the problem of congestion control and avoidance falls into three classes: cooperative, authoritarian, and market. Cooperative solutions, where everyone agrees to be well behaved, are adequate for small numbers of hosts, but tend to break down as the number of hosts increases. Authoritarian solutions are effective when behavior can be easily monitored, but tend to fail if the definition of good behavior is subtle. A market solution is possible. only if the rules can be changed so that the optimal strategy for each host results in a situation that is optimal for all. Where this is possible, market solutions can be quite effective.
Antoher approach to deal with the problem of congestion control and avoidance is to use fair queuing. Consider for example if any host on a local area network generates packets routed to the wide area network at a rate greater than the wide area network can absorb them, congestion will result in the packet switch connecting the local and wide area networks. If the packet switches queue on a strictly first-in, first-out basis, the badly behaved host will interfere with the transmission of data by other, better behaved hosts. To deal with such hosts Nagle proposed idea of Fair Queuing, as dicussed in the next section.
| * * * * * |
Fair Queuing
Fair Queuing [NAG87]
-
The elements pointed out by Nagle, for fair queuing are as given below.
- Seperate queue for each host source.
- Round-robin processing of the queues.
The description of the above points, are related to the figure below.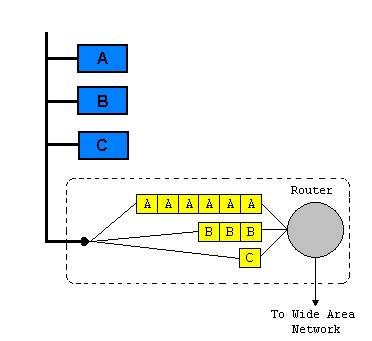
Now considering the above figure, and the points discussed by Nagle, We note that badly behaved hosts can send all the datagrams they want, but they will not thereby increase their share of the network resources. All that will happen is that packets from such hosts will experience long transit times through the network. A sufficiently badly behaved host can send enough datagrams to push its own transit times up to the time to live limit, in which case none of its datagrams will get through. This effect will happen sooner with fair queueing than with first-in, first-out queueing because the badly behaved host will only obtain a share of the bandwidth inversely proportional to the number of hosts using the packet switch at the moment. This is much less than the share it would have under the system where more verbose hosts obtained more bandwidth. This provides a strong incentive for badly behaved hosts to improve their behavior.
However, all is not well with this approach either. It is worth noting that malicious, as opposed to merely badly behaved, hosts can overload the network by using many different source addresses in their datagrams, thereby impersonating a large number of different hosts and obtaining a larger share of the network bandwidth.
- Seperate queue for each host source.
Congestion Control & Fair Queuing [DKS89]
- Congestion Control :
The congestion control methods have two points of implementation.- The first is at the source, where flow control algorithms vary the rate at which the source sends packets.
- The second point of implementation is at the gateway. Congestion can be controlled at gateways through routing and queueing algorithms.
- The first is at the source, where flow control algorithms vary the rate at which the source sends packets.
- Queuing :
Queueing algorithms can be thought of as allocating three nearly independent quantities:- Bandwidth allocation:
This has to do with which packets get transmitted. - Promptness :
It has to deal with question of when to transmit the packet. - Buffer space :
It has to deal with facing decision of which packets to discard.
- Bandwidth allocation:
- Congestion Control :
Notion of User
Independent of the method employed to allocate fair bandwidth to each of the users, the notion of user also require a little mention. It could be either as a single source can be considered as user, or destination, or both in pair can be considered as user. Individual processes also can be candidates of being considered as users. However each of them have subtle flaws too. e.g. A single source could impersonate as multiple user by manipulating the source address, and hence end up eating up larger share of the bandwidth.
Fair Queuing Details
- How to allocate buffer space fairly ?
Drop packets, when necessary, from the longest queue.
- How to deal with variable packet length?
- Bit-wise round robin is ideal.
- Simulate it by estimating finish time.
- How to allocate buffer space fairly ?
- Note : Fair queuing details are discussed at length in the notes of next lecture.
| Top | * * * * * | << Previous Next >> |