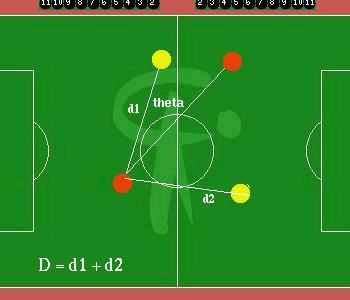
FIg : The values D and theta calculated in a sample situation
The values D and theta can be seen from the following figure where the red blobs represent the active team (player 1 is the active agent while player 2 is the passive agent) and the yellow blobs are the defending team.
FIg : The values D and theta calculated in a sample situation
The significance of their inclusion is seen from the standard Bellman equation for reinforcement learning.
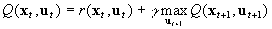
where Q is a utility function from S*A to real numbers. Here S is the set
of states and A is the set of actions.
The total utility value of an action
u
in a state x
is the sum of the immediate reinforcement r
received and the expected maximum utility of the resulting position, weighted
by a discount factor gamma (<1) as it represents delayed rewards.
Here, a utility of the final position must be incorporated to account for delayed rewards expected in the future. Since our scheme does not perform complete dynamic programming by considering each velocity-angle pair, the expected utility of a pair must be heuristically estimated. This is where D and theta come in. D represents how far the active agent has been able to take the ball from the defenders and theta represents the passing opportunities to the passive teammate who has been trying to strategically position itself all the while . These should have a relatively low weight so that they do not override the major factor, namely, moving towards the opponent goal quickly.