Semantic Regularities in Grammatical Categories:
Learning Grammatical Gender in an Artificial Language
Jelena Mirkovic a, Sarah Forrest a and M. Gareth Gaskell a
a Department of Psychology, University of YorkPresented at CogSci 2011
Paper Review
Motivation
In many languages across the world, every noun is associated with a gender. Grammatical gender is typically thought to be semantically arbitrary, though in some languages like French, there are certain probabilistic cues. For example, an e at the end of a noun usually suggests that that the noun is feminine, though there are multiple exceptions and such cues may not be found in most languages. Also, natural gender of a noun influences the grammatical gender, for example, in Spanish, el hombre means man and is masculine, and la mujer means woman and is feminine; in French, l’ homme and la femme, are the respective counterparts. Such a classification, however, is limited to a small set of words which have a natural gender associated with them. Recent attempts have to some extent shown that there are certain cues, like gender-marked articles (Dahan, Swingley, Tanenhaus, & Magnuson, 2000) and phonological similarities (Brooks, Braine, Catalano,& Brody, 1993), which dictate grammatical gender acquisition. This paper attempts to prove that semantic cues in language are at least probabilistically related to the acquisition of gender classes.
Methodology
To test their hypothesis, the authors constructed an artificial language where gender was determined by distributional (co-occurrence of article like determiners) and phonological (suffixes) cues associated with a noun, as given in Table 1.
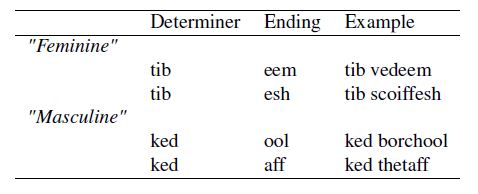
Table 1: Properties of Gender Classes in the Artificial Language
The pseudo-determiners (tib, ked) and the pseudo-suffixes (esh, eem, aff, ool) were chosen from a database of pronounceable English non-words (ARC database) (Rastle, Harrington, & Coltheart, 2002). To teach the new language, words were paired with images from the ClipArt database. The pictures chosen were of human occupations, characters and animals. Using a paradigm for cross-modal learning new languages developed by Breitenstein et al. (2007), the authors were facilitate and evaluate the learning of the meaning and the gender categories of each word. Specifically, over a period of five days, the participants were auditorily presented with every new word 20 times with the target picture and 10 times with a randomly chosen non-target picture, and asked to decide if they pair is matched correctly. No feedback was provided. It should be noted that a determiner-suffix pair was never incorrectly matched, i.e. ked-ool and tib-esh pairs existed, but not ked-esh, tib-ool. The determiner-suffix relationship was probably recognised at this stage. To further assess whether the lexical-semantic relationship was correctly deduced, the pictures were primed with five auditory cues: new words, English picture names, semantically related English words, semantically unrelated English words and non-learned pseudo words as a control set. For example, the picture in Figure 1, was primed with scoiffesh (new word), ballerina (picture name), dancer (related),crow (unrelated) and vedeem (control word). The percentage accuracy in selecting semantically related primes and new words was noted. There were two tests done to assess the learning of gender like classes. First, the new words were asked to be matched to a determiner, i.e. the participants had to tell whether the word is a tib word or a ked word. Second, a new set (called the generalisation set) having new eight items per gender class, half of which had inconsistent determiner-suffix pairs was shown post-training, and the change in accuracy from consistent to non-consistent determiner-suffix pairing was observed.

Figure 1: An example of the pictures used
Results and Discussion
The determiner selection problem provided a good example of how participants learn distributional regularities. One of the hallmarks of grammatical gender processing is the article-noun correspondence. Using this experiment, the authors were able to successfully demonstrate that participants learned the distributional property as shown in Figure 2.
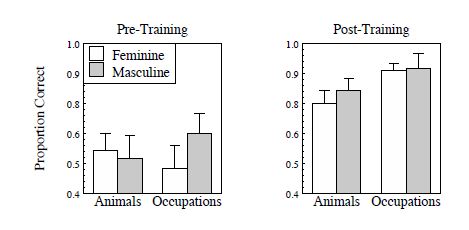
Figure 2: Determiner Selection Performance
The result for the generalisation set is even more striking as shown in figure two. Incorrect, determiner-suffix pairing led the participants to falter both in the word picture matching and the determiner selection tasks. This result demonstrates that we learn semantic regularities while learning new gender classes. What is amazing about this result is that, distributional regularities also seem to affect our learning of new words. What I found particularly interesting about this work was the learning approach they used. The multi-modal (auditory-visual) learning strategy with the correct pairing being probabilistically present closely simlates the native meaning learning processes in humnas. However, with a limited training set of 128 pictures and few phonological markers, the result given here may not be true reflection of the learning efficiencies and processes.
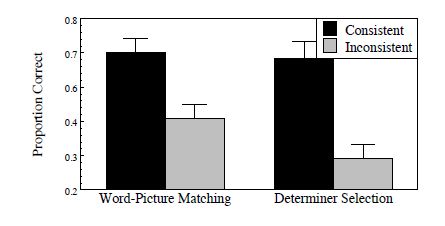
Figure 3: Performance on Generalisation Set
References
- Breitenstein, C., Zwitserlood, P., Vries, M. de, Feldhues, C.,Knecht, S., & Dobel, C. (2007). Five days versus a lifetime:Intense associative vocabulary training generates lexically integrated words. Restorative Neurology and Neuroscience, 25, 493-500.
- Brooks, P. J., Braine, M. D. S., Catalano, L., & Brody, R. E.(1993). Acquisition of gender-like noun subclasses in an artificial language: the contribution of phonological markers to learning. Journal of Memory and Language, 32, 76-95.
- Dahan, D., Swingley, D., Tanenhaus, M. K., & Magnuson, J. S. (2000). Linguistic gender and spoken-word recognition in French. Journal of Memory and Language, 42, 465-480.
- Rastle, K., Harrington, J., & Coltheart, M. (2002). 358,534 nonwords: The ARC nonword database. The Quarterly Journal of Experimental Psychology Section A, 55, 1339-1362.