
|
Object Detection - A Computational Model
Introduction
When we are 'attentive', we are selectively responsive to some stimuli over others. Visual Attention retricts our focus to the relevant information in our visual field and it is one of the most important
tools that we have for efficiency in tasks like object detection, scene recognition etc. It is not very clear as to what are the aspects that guide our attention but two prominent candidates are the
top-down and bottom-up features.
Bottom-up Approach
This task-independent mechanism to guide attention uses the saliency of the objects in the visual field by directing our attention to the regions/objects with high saliency.
Top-Down Approach
This is a task/goal dependent mechanism to guide atention. While searching for a specific object, the top-down mechanism takes into account the features of the object and guides are attention to areas in the visual field which are likely to have the object.
Recently, work has been done which has efficiently combined these two approaches to model Visual Attention. Working along these lines, in this project, I would like to develop a model for Visual Attention which would combine the top-town and bottom-up approaches and perform efficiently in the task of object detection.
Proposed Methodology
To develop this retricted model of Visual Attention (retricted because I would strive for its efficiency in a limited domain - object detection), I would combine the cues obtained by various mechanisms (top-down and bottom-up) to guide attention.
Top-Down Information
Some aspects which can help us in object detection are the contextual cues ([1] and [4]) and the feature based cues ([1]). To gather the top down information, we will extract these and combine with the
bottom-up cues for object detection.
The feature-based cues are object dependent and help guide our attention. When searching for a rope, we tend to focus on long, thin, coiled objects in the visual field.
The relevance of contextual cues can be seen from the fact that when searching for a car (given an image of the road), we tend to ignore the sky (top part of the image). [4] provides us with a
computational model for contextual cues.


The above images (from [4]) give an example of contextual cues when searching for a person.
Bottom-Up Information
A very popular model for obtaining the saliency information (bottom-up) is the Itti-Koch model and this is the one I will be using to obtain the bottom-up cues. This model takes into account the features
like color, orientation and intensity in a task-independent way[2]. Here are some images which show the saliency map given by the Itti-Koch model.


The saliency map has been generated using the codes obtained from [5].
Testing the Model
Besides efficieny in the Computer Vision task of object detection, I also aim to develop a model which resembles the human mechanism of Attention. To analyze the proximity between the two, I would compare the areas that the model declares as likely to contain the object with the areas which the humans eye fixates upon when doing a similar task. Data sources for this purpose can be taken from the web eg [8]
Relevance
Object detection is obviously a very important area of Computer Vision. One very naive approach to it is to scan every region of the image for a likely match with the target object but this is a very
inefficient method. Instead we can try and duplicate the amazingly efficient mechanism that humans use. Modelling visual attention helps to increase our efficiency because we can restrict our focus to the
areas likely to have the object. Also, developing and testing such a model gives us a better insight about the features that influence and guide our attention.
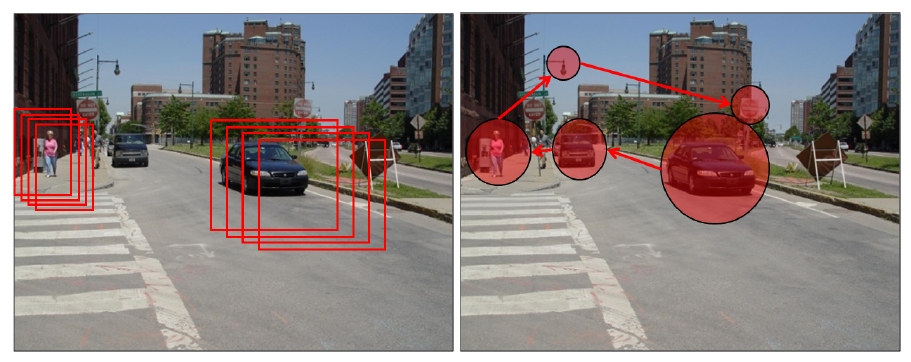
The above Image (from [1]) shows the naive approach vs the approach used by humans for object detection
Previous Works
A lot of work has been done on modelling visual attention and implementing these models for tasks like object detection. A lot of focus has been on recognizing the aspects which influence and guide the
visual attention. The most prominent of these have been bottom-up sailency [2], top-down information (feature based and contextual cues [4]).
Some computational models of visual attention have been implemented based on the above eg bottom-up and contextual cues ([4]), bottom-up,feature-based and contextual cues ([1]).
In general, the models based only on bottom-up approaches have done well when it comes to tasks like free viewing but for goal-dependent tasks like object detection, models based on top-down cues
perform better. However, using the bottom-up cues in addition to the top-down cues for object detection helps increase the efficiency[1].
Also, using both contextual and feature based cues help us model human attention better than if only one is used [3].
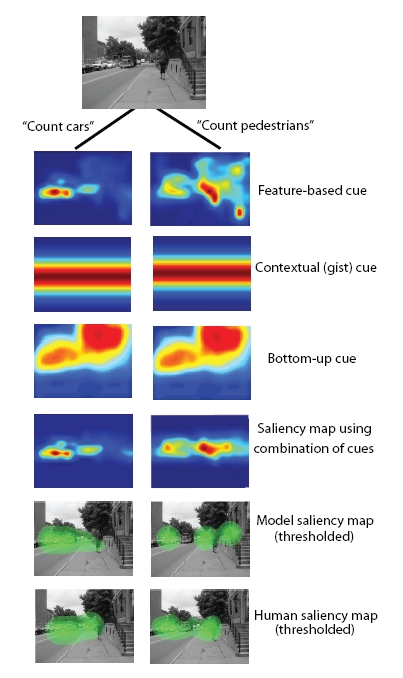
Below is the computational model (from [1]) used for object detection which combines the top-down (contextual and feature-based) and bottom-up cues (image taken from [1])
References
Code and Data Sources
- Shubham Tulsiani