
|
A stochastic model of human visual attention with a dynamic Bayesian network
- Akisato Kimura, Derek Pang, Tatsuto
Takeuchi, Kouji Miyazato, Kunio Kashino and Junji Yamato
CoRR April 2010
Introduction and Motivation for the Problem
Humans have a very useful mechanism of visual attention which allows them to focus only on the areas of interest in the visual field. Simulating this in robots would be a significant step ahead in some of the applications in computer and robot vision searches. This would be used as a pre-selection mechanism as it would give us the areas which are likely to contain the objects of interest.
The attention in humans is believed to be controlled by the following two mechanisms -
Attention is generally simulated using one or a combination of these approaches.
This paper deals with the problem of coming up with a suitable model for visual atention.

The Approach Used
According to a prevelant approach (feature integration theory), several primary visual features(eg colour, orientation) are first processed
and then integrated into a saliency map. Another claim (signal detection theory) is that the elements in visual field are represented as
independent random variables. This can be validated from the observation that when told to search for an object inclined at 45 degrees,
our eyes never wander to the distrator in easy search but they may do so in case of the hard search.
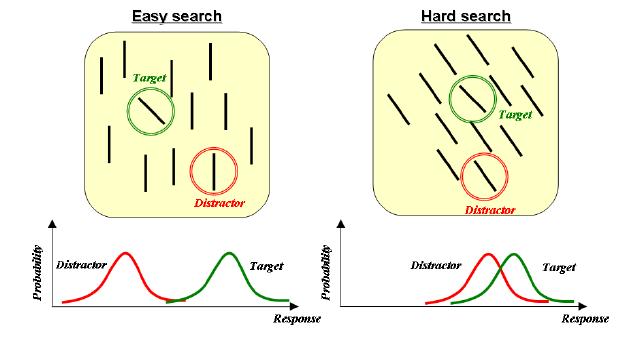
A combination of these two is used to obtain a stochastic sailency map where each pixel is a random variable. Also, to take into account the task dependent nature of attention, the paper also takes into account the eye movement patterns.
The Visual Attention Model
Since we want to simulate human attention, the only input to the model should be the various frames of the video. To take into account the intention, we also use a Hidden Markov Model layer to represent eye movement patters. The flow diagram of the model is the following -
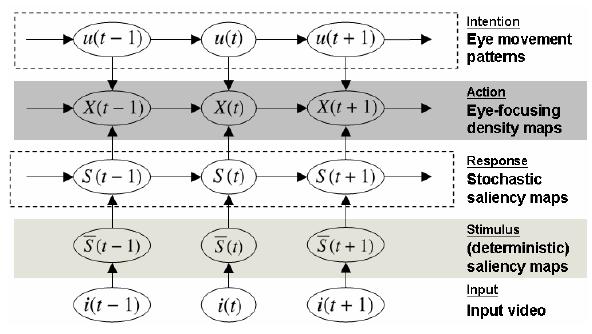
The proposed model for visual attention basically comprises of the following layers-
Conclusion
The problem of modelling visual attention is a challenging one and there are many ways to approach it. This paper proposes a new method to predict likelyhood of human attention on various regions which combines the saliency features and the eye movement patterns and the results obtained are an imprvemt over the previous ones. The challenge is to further improve these and/or realize real time attention models which perform on real time videos instead of video frames.
References
- Shubham Tulsiani