
|
2 - Probabilities, Entropy
Probabilitiies on Given Data
On analysing the given text, the probablities of occurences various alphabets were clculated which are representated as follows
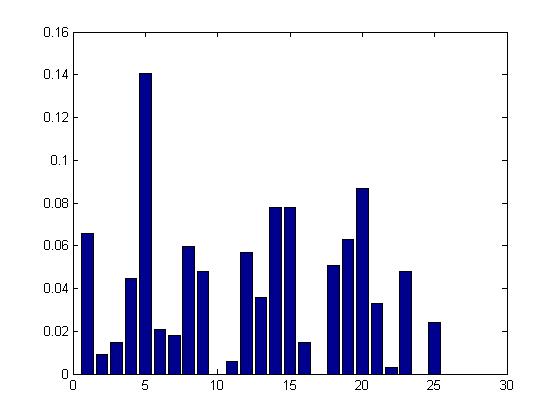
The numbers from 1 to 26 represent the corresponding alphabets and the height of the bar represents the probability of their occurence in the
given data.
Entropy of Given Data
Using the formula than Entropy= -1* Summation of P(i)*ln(P(i)) where P(i) is the probability of the occurence of the ith alphabet
, we get
Entropy = 2.8431
Analysis of Larger Data Set
For this part, I took the data from Wikipedia about the frequency of occurence of various alphabets in the whole of English Language.
The probabilities of occurence of various alphabets are as follows -
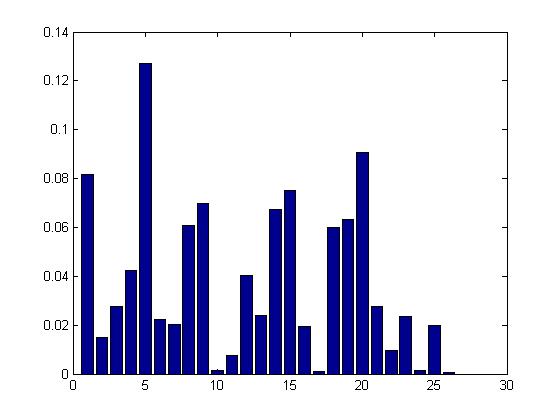
The numbers from 1 to 26 represent the corresponding alphabets and the height of the bar represents the probability of their occurence in the
given data.
The entropy of this distribution is 2.8944
The two distributions have many similarities like the alphabet 'e' occurs most frequency in both followed by 't'. Also, the letters like 'z','x'
have low probabilities in both. This shows that there might be some kind of frequency pattern which the english alphabets tend to follow.
Also, the entropies of both the distributins are similar.
- Shubham Tulsiani