I am broadly interested in the area of high-performance computing. My current research interests include scalable parallel communications, modeling and optimizing scientific workflows, data movement optimization, parallel I/O, and application performance modeling/analysis. Below are a subset of the problems we are currently working on. Email me for an in-depth discussion.
Job scheduling on supercomputers: Several jobs are submitted to a supercomputer. Jobs vary in size and time. Jobs also vary in the communication characteristics and there may be other dependent jobs. Therefore, a job scheduler needs to not only consider the size and time of a job, but also several other job-specific features to obtain the best system throughput.
Online data analysis of scientific simulations: Analysis of parallel simulations that generate a huge amount of data (terabytes) is a daunting task. We're working towards developing ML algorithms that are capable of handling this large volume of data to extract meaningful analyses.
Performance analysis of parallel programs: Analysis of parallel programs helps understand the source of poor performance (i.e. high execution times). This includes profiling parallel codes to analyze inefficient memory accesses, NUMA placements, and time-consuming communications in the intra- and interconnect among other factors. We also work on visual profiling to better understand the performance bugs.
Enabling near-memory analysis and visualization of scientific codes: Data analysis and visualization of scientific computing gives us insight into the simulations. With data size growing larger, it has become important to analyze and visualization in situ (i.e. where the data is produced). We look into the multiple challenges involving data movements in these cases.
Modeling parallel programs: We're looking into the usage of active learning for predicting parallel program performance, including parallel I/O performance.
Communication optimization: We're generally interested in the fascinating topic of communication optimization and topology-aware process mapping. We also work on data movement optimization for parallel I/O.
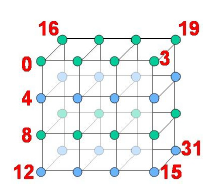
Collection of compute nodes and network links is all we work on. The figure shows a 3D mesh arrangement of compute nodes.
Prospective Students/Interns
I'm looking to hire MS/PhD students who are (1) Interested in computer systems and (2) Good in programming (C/C++).
If you're interested to work in the field of high performance computing, please select High Performance Computing as one of your top preferences while applying to IITK and send me an email with the subject line "Interested in HPC".