| Course Number and Title | CS625: Advanced Computer Networks |
| Instructor | Dr. Bhaskaran Raman |
| Lecture Number | 28 |
| Date of Lecture | 31st October, 2003 |
| Topic of the Lecture | Internet Measurement Studies |
| Scribe | K Vikram (vikram@cse.iitk.ac.in) |
| References | [PF95] [AF99] |
Introduction
In the process of designing protocols for operation in networks, especially the Internet, there is often the need to test its working before deploying it on the actual network. Such a kind of testing is usually done by a simulator which has a model for the Internet and simulates its behaviour by using this model. This approach of testing first on a simulator and then in the real world has obvious advantages in terms of effectiveness, cost and convenience. For one thing, on a simulator the external environment is in our hands and we can vary all the external factors as much as we desire even though these variations might occur rarely in practice. Secondly, if there are bugs in the protocol, they are better removed before using them in a real network This is best done on a simulator, since even if a bug manifests itself, it does not cost as much as it would have otherwise. Finally, it is always more convenient to work with just software, rather than going out onto the field and dirtying one's hands.
Since simulations are such an important part of research not only in networking, but also in other fields we need to have simulators which work on a model which is as close as possible to the real world. The closer the model is, the more accurate the results of the simulations are. Modeling is therefore an important integral part of research. In this lecture, we look at how we can model the Internet and its various components.
A bit on Probability
Since the number and complexity of the factors affecting the Internet is so huge, it is generally not possible to come up with an exact analytical model. Much of the behaviour, especially that of packet arrivals are instead modeled statistically. We refresh ourselves with some bit of statistics here in order to understand the nature of these models.
One effective way of modeling arrival of packets or any events is to assume that each event is independent of the other. In other words, the system does not maintain any history or keep track of how many and what kind of events have already occurred. Such a model often works out well in practice. This kind of distribution of events is known as the Poisson's Distribution. To formally define it, consider the positive real number line and place dots on it randomly. Placement of a dot on this line is independent of the other dots already present or about to be placed. Consider any unit interval on this line. This interval can have any number of dots ranging from 0 to ∞ (infinity). The probability that this number is n, given a particular average value of λ, is given by
p(n) = e-λ λn / n!
As one can see, this is a discrete normalized probability distribution since the probabilities for all possible values of n add up to unity. The average value as well as the standard deviation of the distribution is λ. The above is the standard Poisson's distribution and it typically is used to model the number of packets/events that arrive in a fixed interval of time. The placement of a dot on the number line corresponds to the generation of an event at a particular time instant on the timeline.
Very often, one is not worried about the exact time of arrival of an event, but about the interval of time between successive packets. Knowing the distribution of the exact arrival times, we can work out the distribution of the inter arrival times. In the case of the Poisson's distribution, it can be shown that the inter arrival distribution is the Exponential Distribution, which is given as follows
f(x) = λ e-λx
This is a continuous distribution, in contrast to the Poisson's distribution, since the value of the inter arrival (units could be anything depending on the value of λ) could be any positive real value. These distributions are also suitable for modeling user generated events.
Modeling of the Internet
What/How can we model?
The question of which kinds of events to model in the Internet could have many answers. Usually, we always model the flow of traffic on the Internet by modeling some aspect of it. Traffic modeling can be done at two possible granularities. One is at the level of packets themselves and the other is at the level of connections. For packets, details such as the number and the size of the packets also need to be supplied. For connections, the number of bytes could be required.
Traffic modeling can be done for protocols such as Telnet, FTP, NNTP, SMTP, HTTP or even RTP (used for Audio/Video). Since we are talking about modeling in the context of the Internet, modeling HTTP is very important. Here we would not be interested in the final model for each protocol, but the methodology of coming up with a model. The usual method is to first collect a lot of traces. These traces could be either connection traces or packet traces. Connection traces would be quite small; for TCP we just need the SYN and FIN packets. The packet traces would require collection of other details such as the connection time and number of bytes, etc. Trace collection might take a long time, but if just the information required can be obtained easily then a lot of time can be saved. In the case of TCP, for example, by just looking at the TCP header, we can get to know all that we require.
Subsequent to the collection of traces, we need to explain these traces by fitting it to some model. There is no straightforward way to think out a model; it involves insight and creativity into the nature of the system being modeled. Nevertheless, once a model has been thought of, its accuracy can be tested objectively by matching it against the observed traces. Such a procedure can also be used to set the values of certain parameters within the model. Matching a proposed equation against a collection of observed data can be done by methods such as regression. Linear regression involves finding the best fit line for a given plot. Linear regression can be used for non-linear curves as well. Suppose a model gives the relationship between a pair of variables x and y as y = λe-λx then we plot the logarithm of the actual values of y against values of x and apply linear regression on it.
"The Failure of Poisson Modeling"
Although network event arrivals have often been modeled using the Poisson distribution, they are usually done so only for its simplicity. A lot of studies[1] have shown that packet inter-arrivals are not exponentially distributed. Here we discuss the appropriateness of Poisson modeling of certain events and suggest ways of correcting errors that might have been introduced, as proposed in [1].
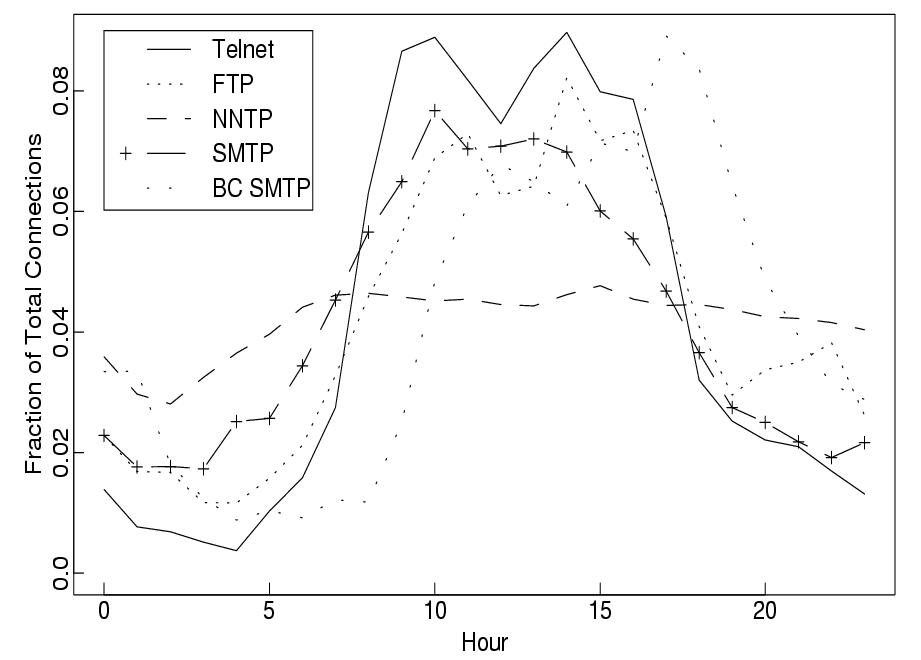
Two sets of traces of wide area network (WAN) traffic have been collected and analyzed[1]. The first set consisted of TCP SYN/FIN connection start/stop packets only. These packets are enough for the measurement of connection start times, durations, the TCP protocol used, participating hosts and the data bytes transferred in each direction. The pattern of connection arrivals has been observed to follow a 24-hour pattern. Graphs of total connections vs. time for a lot of application layer protocols such as TELNET, FTP, NNTP, SMTP and BC SMTP were constructed, as shown in Figure 1.. It was observed that a Poisson distribution did not model their behaviour correctly as the arrival rate varied from one part of the day to another. To still keep using the Poisson modeling, the behaviour was modeled as constant rate Poisson distributions within 1 hour intervals. This ensured a proper match against the observed data. For a better fit, even 10 minute intervals could be used.
Figure 1: Mean hourly connection arrival rate in terms of the fraction of total connections
The data shows that for TELNET and FTP session arrivals are modeled this way. Over one hour other protocols were not well modeled by the Poisson distribution, even if 10 minute intervals were used. The primary reason was that TELNET and FTP sessions involved events that are generated by humans and usually independent of the dynamics of a network. Most other protocols had far more bursty behaviour to fit into the Poisson model. This was primarily because events in them are rarely generated by humans. For instance in SMTP, a lot of mails could be machine generated especially when two SMTP servers talk to each other. Also, even though it might involve an event from a human who sends a mail, his mail might generate a large number of further events, especially when his mail is directed to a mailing list. Even for HTTP, which forms the bulk of the traffic on the Internet, this modeling does not work out quite well. This is because another factor called the think time comes into play here. Think time is essentially the time required by a human to read an HTML page before he decided to click on a link on that page. Modeling this think time is crucial for the analysis of HTTP traces.
The second set of traces looked at also the packet arrivals within a certain connection. This set does not observe a large number of TCP connections, so they have not been used for the modeling of TCP connection arrivals. Packet arrivals for mainly TELNET and FTPDATA (the data transfer part of an FTP session) were observed. In TELNET, the study was restricted to the originator side of the connection and not the responder. The observed traces do not fit into the exponential model and the logarithm plot of the data was observed to be highly non-linear. A better model of this used the Pareto distribution. One feature of this distribution is that a major part of something is accounted for by a significantly minor part. For instance, in compiler optimizations, the 80-20 rule states that 80% of the performance improvement is due to 20% of the optimizations. Such a distribution models the bursty nature of traffic very well. Also, in the Pareto distribution it is possible that the variance and/or the mean turn out to be infinite.
Although for FTP sessions the Poisson model could be used successfully, for FTPDATA that is not appropriate and its distribution is characterized by a heavy tail in the probability density function as shown in Figure 2. Such a distribution has a finite non zero probability for very large values.
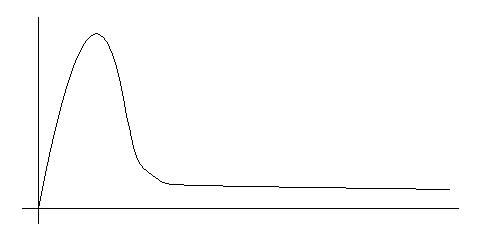
Figure 2: Probability Density Function of a Heavy Tail Distribution
The tail in a heavy tail distributions tends to have a lot of influence on the value of the average. For transferring large files, typically FTP is used. Therefore an FTPDATA connection, there is practically no limit on the size of a file sent in one session and often there is a considerable probability of very large files being sent. Even one such occurrence of a file transfer can significantly influence the behaviour of the protocol.
Evaluating TCP
Once a model has been decided upon, evaluation of a protocol can proceed. As the de facto protocol used on the Internet is the TCP, we discuss in depth issues that come up during the evaluation of TCP. Although it looks deceptively simple, the Transmission Control Protocol (TCP) is a subject of much research since there are a lot of subtleties to it. Even small seemingly insignificant changes in its design or parameter values can lead to a huge variation in the perceived behaviour. A lot of people have worked on and will possibly keep working on improving TCP by making appropriate modifications to it. These modifications have to be rigorously tested and evaluated before they can be actually deployed. Various testing methods have been proposed for the evaluation of TCP, but they have certain shortcomings. Simulations are difficult due to the large variations in the versions of TCP and testing on the Internet might endanger its integrity. Here we discuss certain guidelines which should be kept in mind while experimenting with TCP.
Which version of TCP?
When one proposes a modification in TCP, its testing has another issues involved which is that of which other orthogonal features of TCP one should use. This usually can be broken down into two separate issues. One is which TCP should be used as a baseline and the other is to which version of TCP should the proposed modifications be made. Here we are mainly concerned with the second question. Typically we might three options to choose from when we decide which version of TCP to use. We may use:
Features which are widely used practice
Features which are good for performance and exist in many OS implementations, but are usually not turned on
Features which are experimental
Then there is also the question of whether the evaluation should be simulation based or implementation based. Only after answering these questions should one start modeling the changes to TCP.
The following guidelines which indicate which features of TCP should be used, would be helpful. The important features of TCP that should be present in all versions of TCP used for experimentation are:
Basic Congestion Control: Mechanisms such as slow start, congestion avoidance, fast retransmit and fast recovery are part of the standard end to end congestion control and are present almost all versions of TCP. Slow start and congestion avoidance are required by the standard to be present, whereas fast retransmit and fast recovery are recommended for the purpose of enhancing performance.
Extensions for High Performance: The standard versions of TCP have a fixed upper limit of 64KB on the advertised window size. This limit is somewhat artificial and is due to the limited space in the TCP header. In order to use the bandwidth on a link fully, the window size required is given by the equation: W = B x R, where B is the bandwidth (in bytes/second) and R is the Round Trip Time (in seconds). This means that in networks with high bandwidths and also high round trip delays the window size required could go much beyond 64KB. Therefore for research purposes this artificial restriction should be lifted. Nevertheless, this could lead to a rapid exhaustion of the sequence number space. To combat this, mechanisms such as PAWS (Prevention Against Wrapped Sequence numbers) need to be used. PAWS, in turn requires the use of timestamps in the protocol. This involves adding a 12 byte timestamp to each packet. This option also helps in the accurate determination of RTT.
Selective Acknowledgments (SACK): Instead of using only the default cumulative ACK mechanism of TCP, the selective ACK (SACK) option could be used to retransmit more intelligently. Since this option is expected to be widely implemented in most OSes, it should be included while experimenting with TCP.
Delayed Acknowledgments: Delay of sending ACKs, for instance sending ACKs for alternate packets, should also be part of the version of TCP experimented with.
Nagle's Algorithm: This algorithm has been used in many TCP implementations for combining small bits of data produced by applications, into larger segments. Since this affects the performance of the protocol by interfering with HTTP, NNTP protocols and with the Delayed ACK mechanism, it should be considered during the testing of a feature in TCP.
Apart from these, which are standard extensions to TCP, certain other extensions have also been proposed and are likely to be part of TCP in future. Researching with these features would also provide some insight into their effectiveness. These features include:
Larger Initial Windows: Based on the segment size, an initial window of upto 4 could be used.
Explicit Congestion Notification (ECN): The only way that a host can infer about possible congestion in the network is through a timeout on a packet. If a router is involved in the dropping of a packet which leads to this timeout, the router itself can notify the source host about congestion instead of simply dropping the packet.
Simulation vs. Implementation
Simulation
Simulations have been successful in evaluating the performance of protocols,
in particular TCP. Various kinds of simulators from the standard ones to hand
crafted ones have been used. Often it is a difficult decision to make about
choosing a simulator for testing purposes. The general guideline is that one
should choose that simulator which best models one's system under consideration.
While evaluating TCP, one should also make sure that all the recommended
features of TCP can indeed be simulated. Using a simulator has significant
advantages:
Cheap, as it does not require costly and elaborate equipments. Only a single machine and the simulator software is required.
Various scenarios, even those that rarely occur in practice can be studied. Very complex topologies that would be difficult to install can also be tested quite easily.
Most of these scenarios can be generated quickly as well. Results are, therefore, obtained a lot faster. This means that a lot of ideas can be testing in a much lesser timeframe than otherwise.
Even setups that current technology would not offer, such as say, terabit links could easily be examined.
One important advantage of using the simulation approach is that of repeatability. If desired, the behaviour of the network could be made deterministic under the influence of a particular protocol. Debugging would be significantly easier in this case. On a real network or on a testbed, where there are a large number of factors this would not be possible.
On the other hand, there are a few disadvantages as well:
Exact simulations of real world protocols are rare. Invariably, certain assumptions and certain simplifications are made to a protocol in order to make it simulatable. In general the version of the protocol used in practice and the version used in a simulation would inevitably be different. Such abstract implementations of a protocol might not always produce reliable results.
Non-network events are not modeled in typical simulators. For instance a heavily loaded machine might introduce jitters of the order of a timeout. This might have an impact on the burstiness of a TCP connection on a very fast network.
Cross traffic is difficult to model on a simulator. Modeling competing flows requires more work and researchers usually choose a simple, but inaccurate model. Even simple topologies for competing flows, such as the dumbbell topology is difficult to analyze accurately on a simulator.
Implementations
Simulations, although they provide an easy way to test one's ideas, are not
enough for the analysis of the working of a protocol. Testing on the field would
require a lot of other issues to be considered. In particular, if a particular
protocol does not behave as expected it is possible that this is due to some
non-network factor like a slow operating system. The problem could also be in
the implementation of the other layers of the system.
Using testbeds is an attractive option for TCP tests. The problems associated with real world tests are alleviated to some extent. One has complete control over all the components in a testbed, much as in simulations. The disadvantages of using simulations are also absent. For example, real versions of TCP could be used. Also the influence of scheduler delays can be tested. Nonetheless, they also suffer from certain disadvantages. The available equipment might restrict the scope of the tests. The cost of setting up and maintaining a testbed is also high. Another disadvantage is that if commercial OSes are used on the machines, then there would be no way of changing their TCP implementations. Open source OSes like UNIX and its variants can be used, but it might not accurately model the most popular OS being used in a particular environment.
Another option is to use emulation. An emulator models the network path between two real hosts. An emulation, in this sense, is a mix of both a simulation and a testbed. For example, bandwidth can artificially be constrained on certain parts of a testbed or a real network. Linux itself has certain modules that restrict the bandwidth of an outgoing network interface. Emulations also in a way abstract the real behaviour of the system like a simulation does. It therefore does not do much better than simulations, although interactions with real world networks can be examined.
The most realistic results are given by live Internet tests. Even though they might produce valuable information about the behaviour of a protocol, they are very difficult to setup. They might even create problems on the Internet.. The process could be extremely costly as well. The test might include hosts that span difference administrative domains. In such cases especially it is difficult to control all the components of the test. Maintenance costs of these test hosts would in particular turn out to be very costly. Issues of security and trust might cause some of these problems. Moreover, external conditions on the Internet can hardly be repeated. Therefore, debugging of a protocol could be extremely difficult.
In conclusion, it seems that a proper combination of various kinds of experiments is the best approach to adopt.
References
[1] Vern Paxson and Sally Floyd, "Wide-Area Traffic: The Failure of Poisson Modeling", IEEE/ACM Transactions on Networking, vol. 3, no. 3, pp. 226-244, June 1995.
[2] Mark Allman and Aaron Falk, "On the Effective Evaluation of TCP", ACM SIGCOMM Computer Communication Review, vol. 29, no. 5, pp. 59-70, 1999.