IP Traceback : Some Definitions
Victim : single host
under attack or a network border device, which represents many such
hosts.
Attack Tree : tree rooted at victim, attackers as leaves and every router as internal node along a path between attacker and victim.
Attack Path : unique ordered list of routers between attacker and victim.
Exact Traceback : to determine the attack path and associated attack origin for each attacker.
Approximate Traceback : to find a candidate attack path for each attacker that contains the true attack path as a suffix.
Marking Procedure : executed by routers in the network
Path Reconstruction Procedure : implemented by the victim.
Convergence time : the number of packets the victim must observe to reconstruct the attack path.
Conservative Assumptions
Regarding Attacker
:
can generate any packet.
multiple attackers possible.
may be aware of being traced.
Regarding Network/Router : packet
loss and reordering can happen.
CPU/memory are constrained.
Helpful assumptions
: attacker
sends many packet.
routes are stable.
not many routes are compromised
Node Appending
The simplest algorithm is to mark packet with every router information it travels through. But it has high router overhead and large header size is required. This can lead to unnecessary fragmentation. The problem cannot be solved by reserving enough space as the attacker may start with high packet size to attack. The advantage of this algorithm is that just one packet may give good result.
Node Sampling
In this algorithm the packet is marked with some probability p and the IP address is put in a static field. With a sufficient no of trial the victim deduces the order from the relative no of samples per node. The advantage of this algorithm is that it is difficult for attacker to insert false information if p > 0.5. The disadvantage of this algorithm is its slow convergence and the fact that in case of multiple attack multiple routers are possible to be at same distance.
Edge Sampling
In this algorithm instead of nodes, edges are marked. There are three reserved fields start, end and distance in the packet, which represent the routers at each end of the link and its distance from the victim. When a packet arrives at router and it decide to mark the packet, it writes its own address in the start field and zero in the distance field. If the distance field is already zero it writes its address in the end field ( distance zero indicate that previous router has marked the packet ). Finally if a router doesn't mark a packet it increments the distance field. This algorithm is robust to spoofing because of distance field. Any value for p can be used here. Also the convergence is quick and multiple attacks can be handled as the edges are being marked. The disadvantage of this algorithm is the need of extra space in IP header. Also the contents of any edge further away than the closest attacker cannot be trusted.
Encoding Issue
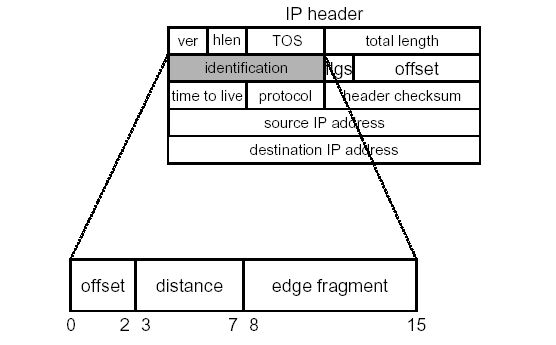
Edge sampling algorithm requires 72 bit of extra space in every packet ( for two 32 bit IP addresses and 8 bit distance field ). If this data be store in IP options, it may lead to slow processing and fragmentation also. If this data be send out of band, it may lead to network/router overhead and also another complex protocol will be required in addition. The approach used is to overload the 16 bit IP identification field used for fragmentation.
Compressed Edge Fragmentation Sampling
Edge is stored as the XOR of the IP addresses of the nodes making the edge. The edge id is fragmented into k parts. When a router decides to mark a packet, it selects one of these fragments at random and stores it in the packet. Additional log2k bits are used to store the offset of this fragment within the original address. To distinguish between multiple edge fragments with same offset and distance hashing of IP addresses is done.
IP Header Encoding
IP header encoding is done as follows :
here k = 8, bits for distance field = 5 and 32 bit hash is used.
Here we are forced to penalize the fragmented packets but we should remember that only 0.25% of packets are fragmented.
Further Issues
Backward Compatibility, IP6
Distributed Attacks
Path Validation
Attack Origin Detection
Author : Amit Rawat (Y3111005)