CS625-ADVANCED COMPUTER NETWORKS
LECTURE 24 (Tuesday, 14 Oct 2003)
SCRIBE: Bhola Ram Meena (Y0097)
PEER -TO-PEER OVERLAY NETWORKS
Peer-to-Peer computer network refers
to any network that does not have fixed clients and servers, but a
number of peer nodes that function as both clients and
servers to the other nodes on the network. In peer-peer networks all
nodes are equivalent . For example Napaster is a peer-peer network for
storing mp3
files.
Classification
of Peer-Peer Networks:
1. Centralized Directory
All information is
stored at central location decided by peer-peer networks.
2. Decentralized Directory
It have no central location
for storing all information.
It can be further classified into two category:
2.1 Unstructured
Networks
It have no restriction on storing data. Data can be stored in any node.
Problem with Unstructured Networks:
It takes long time to search for a
particular item.
2.2 Structured Networks
It solves the above problem by putting restriction on way data is
stored in network.
Structured
Peer-to-Peer Networks
These networks have close coupling
between network topology and data location.
Several distributed data structured have
been proposed for these networks:
1. Chord
2. CAN (Content addressable Network)
3. Tapestry
These data
structures provide the same functionality.
peer to peer
Network Features:
1. Redundant
Storage
Same data is
stored at different places so it can be available if any node goes down.
2. Selection
of nearby servers.
For any data
request , closest server having data is selected.
3. Search
of Data
Data can be searched
in P2P networks.
4. Efficient
Location
P2P networks provide efficeint
location based on keys.
CHORD
Functionality
1. Chord maps key space to node space.
---- It map a given key to a
node which stores data and serves it.
--- Keys can be stored at
particular location.
--- Key space is flat
Chord places no contraints on key it looks up.
--- Support Dynamic node join/leave.
2. Application related functionalities
--- user friendly naming of data.
--- Authentication
we can use secure hash for
defining keys or we can use a secret key so anyone who don't know
secret
key cann't get particular mapping.
--- Replication
chord directly doesn't provide
replication because it assumes that different key means different data.
But
a data can be associated with two keys for proving replication.
Chord doesn't provide
support for searching.
Examples
of applications using P2P networks
1. Distributed Indexing
2. Cooperative Mirroring
Let say different piece of
software is stored at different nodes and if demand for a particular
software is high then there will be load variation in network. Using
P2P networks we can distribute the load over all network.
3. Time Sharing Storage
-- access to data all time.
-- P2P can put more stress on availablity rather the load
balancing.
CHORD
Interface
1. lookup(key)
It return a node corresponding to
key. Key can be any arbitrary string.
2. callback.
Due to join/leave of nodes in network set of keys might
change for a node.
CHORD Look
Up Protocol
---
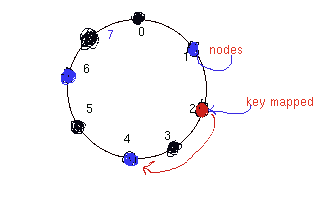
Nodes/keys are hashed using SHA-1 in a circular m-bit space
[0.................2^m-1]
--- IP address of node is hashed.
--- consistent hashing for load balancing
- Key is assigned to
successor node.
Let
consider a network in which nodes are hashed on 1, 4, 6 in 3-bit
space.
Let
key k is mapped to 2 then it will be assigned to its successor node
which is 4.
----
Reassignment happens only after node joins/leave.
---- No
rehashing only resassignment.
Let node 3 joins then it will be
responsible for node 2 .
Scalable
Key location
default way:
Every node maintain pointers
to its successor node and node for a given key is found by following
these pointers.
But this is O(N) time complex.
Optimization:
-- maintain a finger table table with atmost m-entries.
For example a node n will have pointers to following
node:
n+2^0, n+2^1,
n+2^2.............n+2^(m-1)
If a pointer is pointing to NULL node then a node
following it will be pointed.
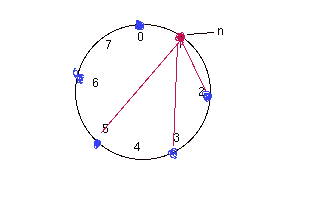
How
finger table works:
1. Nodes stores only small number of pointers. A single
node may not have pointer to succesor of key(k).
2. Node n searches its finger table for node j which precedes k.
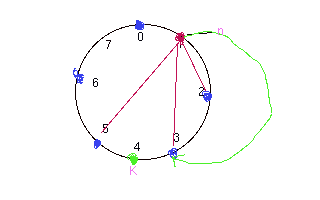
It takes O(logN ) times beacuse it halves the distance in
each look up.
For example .
N0+ 2^i <= k <= N0+2^(i+1)
N1+ 2^(i-1) <= k <= N1+ 2^i
.......
Nm<=k<=Nm+2^(0)
Main
steps when node n joins:
1. Learn of some other node n'
offline.
Ask for successor of n.
2. Initialize own finger table and
predecessor
--- update fingers of existing nodes.
3. Transfer Keys.
Some
Remarks
1. Simultanious join/failure
-- need of r nearest successors
-- need to replicate some data associated with
keys.
2. Protocol can implemented recursively or
iteratively
3. Path length expansion is a important
concern.
--- there is no corelation in distance between
logical space and physical space.
Those nodes which are near in logical identifier space can be far
aparted in physical space.
---- address at overlay node placement
References
1.http://www-2.cs.cmu.edu/~kunwadee/research/p2p/links.html
2. http://en.wikipedia.org/wiki/Peer-to-peer
3. http://www.pdos.lcs.mit.edu/papers/chord:sigcomm01/chord_sigcomm.pdf