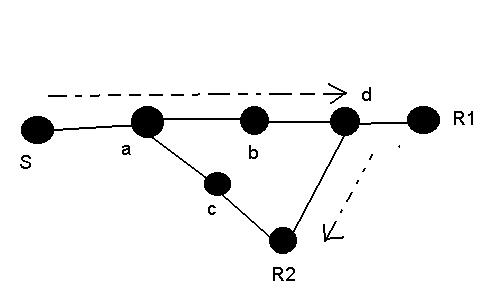
If S wants to send data packets to R1 and R2, then there may be a minimum delay path from S -> a-> c->R2. But to utilize the bandwidth to the max, the route considered will be s->a->b->d->R1/R2.
Advance Computer Networks (CS625)
Lecture No.18 -- Multicast routing 16 sep,2003
Scribe by: VIPINDEEP V (Y3111053)
M-Tech(CSE)
Outline :
Multicasting in LAN
Extended LAN (and unicast routing)
Multi cast in DV routed network
Reverse Path Flooding
Truncated Reverse Path Broadcasting
Reverse Path Multicast
Hierarchial Multicast
What is multi cast...
Muticast in a datagram netwok is the transmission of the data packet to a
subset of hosts.
The basic benefit of multicast is that any source can send down its
data to required destination which is not a single host but can be a
group of hosts sharing a common address. So the sender sees the
destination as a single host. Hence the duty of sender is completed,
once it sends a single data packet destined to the abstract group. Even
the intermediate routers have no idea regarding the exact set of hosts.
If multicast was not supposed to be used, then source has to send
the data packets one for each host. Moreover multicast
encapsulates the actual hosts.
The destination host should subscribe to receive the messages from a
source to that group. The host can unsubscribe whenever it intends
to do so.
There is always a trade off between bandwidth and delays, if we
consider large LAN's
Consider the following network..
If S wants to send data packets to R1 and R2, then there may be a
minimum delay path from S -> a-> c->R2. But to utilize the
bandwidth to the max, the route considered will be
s->a->b->d->R1/R2.
Multicast in LAN:
When we deploy CSMA/CD in a LAN, which can support multicast to a
certain extent. The data can be broadcasted within LAN. If the data is
intended to a destination, then the packet is accepted otherwise it
discards it.
The 48-bit ernet address has a partition dedicated for multicasting.
There is a one-one mapping from the IP address (which is 32-bit) to the
ernet multicast.
Extended LAN and Unicast routing:
Extended LAN' contains a group of LAN's connected via Bridges.
The LANs are connected at data link level.
To learn the paths in network, we will use flooding. But this may give
rise to looping. The reason for looping is that, the same flooded packet
because of the recurrent paths may again come back to sender and in this
way loops infinitely if no prevention mechanism id done (time out to an
extent can remove infinite looping).
Looping can be removed by using spanning tree algorithm.
All branches have path vectors and link state. so it is possible to
learn the shortest path form bridge to bridge. We can designate a bridge
as "root bridge" in the network. The root may be chosen arbitrarily (ex.
choose bridge with least MAC address).
Periodically refresh the root so that when the root is dropped, we
can choose a new bridge as root.
Amount of state:
If Sa represents number of active sources, Ga represent number of
active groups, then the amount of state stored at bridge is proportional
to Ga. Its independent og Sa. We can use a single tree for LAN and
forward the data to the group irrespective of the source of data.
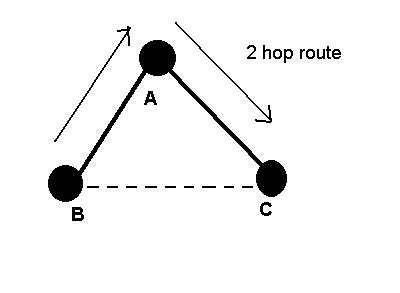
Multi cast in DV routed network:
We can say that, unlike bridged LANS this schema is not suited for
multicasting because no single tree is suitable for all the sources. The
alternate is to have a tree per source. This can put lot of burden on
the routers and hence can be modified to tree per group. Now consider
following situation. If A wants to send data to C then as per this
schema, the packet has to go through 2 hops through B hence tree per
source is comparatively better.
In order to provide a better multicast strategy, the following steps are
taken:
Reverse Path Flooding: In this all the receivers are being flooded.
here there is no notion of group.
Reverse Path Broadcasting
Truncated Reverse Path Broadcasting: In this step we try to
truncate the tree so that the data is not sent to any tree on which
there is group. This method is fairly simple because it needs to be
implemented at the leaves.
Reverse Path Multicasting: This is built on the top of TRPF which will
try to prune up the tree.
Let us see each of these in detail:
Reverse Path Flooding:
The method of sending packets:
A router forwards a broadcast packet originating at source S if and only if it arrives via the shortest path from the router back to S . The router forwards the packet out all incident links except the one on which the packet arrived.
Whenever a source wants to send data packets, it floods all the nodes at the outgoing link except on the originating link. In this the data packets are sent onto a router if there is a reverse path of shortest distance from the next router to the source.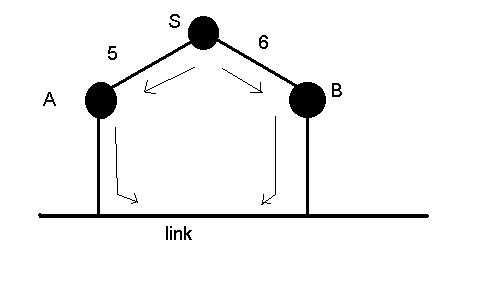
S wants to send data packets onto the link. This is possible through
the two nodes A and B. Both A and B have a shortest path to S( of cost
5 and 6). So the packet is sent to both routers A and B which in turn
duplicate packet on the link. So to avoid this we can consider only one
packet from the source which come along the min cost path . In this
case packet from B may be discarded. In case of a tie, we can select
arbitrarily breaking the tie. This is principle of RPB.
It may look as if we are sending packets on only a single link but the packets are sent to all the places in network.
To implement the basic reverse path forwarding algorithm, a router must be able to identify the shortest path from the router back to any host which is available from routing tables.
Reverse Path Broadcasting (RPB)
To eliminate the duplicate broadcast packets generated by the RPF algorithm, it is necessary for each router to identify child links in the shortest reverse path tree rooted at any given source S. Then, when a broadcast packet originating at S arrives via the shortest path back to S, the router can forward only to child links.
The basic scheme is to identify parent router for any router so as to reach each of its source.
Truncated Reverse Path Broadcasting:
In this step we try to truncate the tree so that we not send data packets to the tree having no members. SO we are going to prune away the leaf nodes (groups) for which the packet may not reach. This is a two step process:
1.Identify the leaves
2.Detect the group membership
Consider the following topology: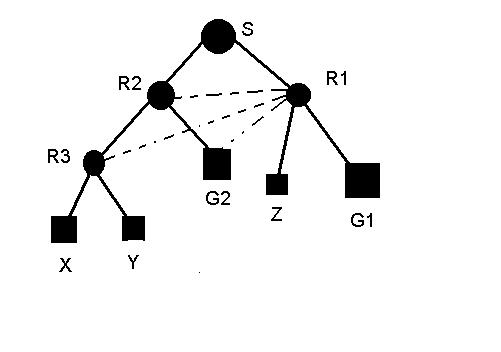
If we have every router periodically send a packet on each of its links, saying This link is my next hop to these destinations then the parent routers of those links can tell whether or not the links are leaves for each possible destination. Then we can identify the leaves.
Once we identify leaves, our next duty is to detect whether or not members of a given group exist on those leaves. To implement this , the hosts periodically report their memberships.
When a multicast packet with source address S and destination group G arrives from the next hop link for S, forward a copy of the packet on all child links for S, except leaf links that have no members of G.
In above S is source wants to send data packets to a Group (say G1). The data packets are forwarded to r2, r1. Then to r2 and to leaves. But it can be seen that there is no need to send the packets to r2 as there is no member of the group under its hierarchy( as we are dealing with trees).
No router uses the leaves to reach the source. In above we can say that r3 uses r2 to get to the source. So we can have groups propagating up the tree. So if we have no group members then we can truncate at the leaves.
Reverse Path Multicast:
This is built on the top of TRPB which will try to prune up the tree. We will build tree for every active source.
We shall start with truncating reverse path routing. The basic emphasis is made on "non-membership" reports which will propagate up the tree. Whenever thee are no members down the hierarchy of a router node (router ), it sends non-membership report to its predecessor(s). In the previous example, Z sends NMR to R1. So that the data packet addressed to the group is not sent to this node.
When a node contains more than two successors (R3 above), then that node sends NMR oly if it gets NMR from all its successors (similar to logical AND). So if R3 gets NMR from X and Y then it sends NMR to R2.
NMR state:
proportional to (Sa*Ga).
This implies that we are maintaining per source tree and per group information.
COST:
The cost of RPM is same as TRPB + cost of storing, forwarding and processing of NMR messages.
NMR may be timed out. NMR refresh is done so as to track a new node(group) in the network. NMR messages should be positively acknowledged.
Hierarchial Multicast
Large multicast routing domains can be decomposed into multiple subdomains, organized hierarchically, such that one subdomain is treated as a single link in a higherlevel domain to scale the multicast service up to large internetworks.
There can be two types of links - one is oint to point. This kind of link may be extended from one router to another within sub domains. A link may be multi access iff the multicasted packet reaches all the subdomain routers connectd to it.
If this condition is satisfied then we can use the same
protocol structure for hierarchial multicasting also. Oe typical architecture is
shown below.
Routing protocol for multicasting are specific for the underlying architecture