APPROXIMATE CELL DECOMPOSITION
INTRODUCTION
:-
·
This approach has
a basic difference with exact cell decomposition approach. Here the cells have
a pre-specified shapes, which are generally rectangloid.
·
Because of this
prespecification of shapes of cells we are not able to represent the free space
exactly.
·
Thus the name
approximate cell decomposition.
·
And as in the
exact cell decomposition approach, a connectivity graph is found out
representing the adjacency relation among the cells and a path is searched.
GENERAL DESCRIPTION :-
·
A Rectangloid represents a closed region of the following
form in a Cartesian space Rn :
{(x1,x2,…..,xn)
/ x1 Є [x1’,x1’’],
…. , xn Є [xn’,xn’’]}
.
The
differences xi’’ –
xi’ , for i = 1, 2, … , n are called the
dimensions of the rectangloid. And none of these dimensions can be zero.
·
CB represents the
C-obstacle region, and D represents the rectangloid. Let R represents the space inside D. i.e. R = int(D).
Then
Cfree = R \ CB.
·
A rectangloid decomposition P
of Ω is a finite collection
of rectangloids {κi}i=1,2,..,r
such that :
-
Ω is equal to the
union of κi i.e. :
Ω
= union of(κi)
-
The interior of κi’s do not intersect, i.e. :
For all i1, i2 Є [1,r] i1 ≠ i2 : int(ki1) ∩ int(ki2) = φ.
Each rectangloid ki is called
a cell of the decomposition P of
Ω.
·
A cell is classified as :
- EMPTY, if
and only if the interior does not intersect with the C-obstacle region, i.e. int(ki) ∩ CB = φ
- FULL, if
and only if, ki is entirely contained in the C-obstable region.
- MIXED, if a cell is neither empty nor it
is full it is mixed.
·
Two cells are called adjacent if
and only if their intersection is a set of non-zero measure in Rm-1.
·
The connectivity graph of the
decomposition P of Ω is a non
directed graph G, whose nodes are the EMPTY and the MIXED cells of P
and the nodes of connected by a link if and only if the corresponding cells are
adjacent.
·
Given a rectangloid decomposition P
of Ω a path is defined as a
sequence (kji)i=1,2,…p of EMPTY or MIXED cells such that
any two consecutive cells in this sequence are adjacent cells.
·
A path that only contains EMPTY cells is called an E – path.
·
A path that contains at least one MIXED cell is called a M – path.
HOW TO FIND A FREE PATH :-
Given
the initial configuration of the robot qinit
and the final
configuration of the robot qgoal both belonging to the
Cfree if we can find out an E – path (kji)i=1,…,p such that qinit Є kj1 and qgoal Є kjp a free path can be found
out which joins the initial to the goal configuration using the E – path linking qinit
to qgoal by a polygonal line whose vertices are the
points Qj which belong to the
face which is common between each of the two adjacent cells of the E – path.
Or in other words,
Qj Є int(Bj), where Bj = boundary(kji) ∩
boundary(kj(i+1)) , j= 1,… p-1
THE BASIC ALGORITHM :-
1.
Compute a rectangloid decomposition P1
of Ω. Set it to 1.
2.
Search the connectivity graph Gi associated with the
decomposition Pi for a channel connecting the initial cell
containing qinit to the
goal cell containing qgoal
. If the outcome is an E – path return success. If the outcome is an M – path goto 3. Otherwise return failure.
3.
Let Mi be the M – path generated at step 2. Set Pi+1 to Pi .For every MIXED cell k in Mi compute a
rectangloid decomposition Pk
for k and set Pi+1 to [Pi+1\{k}]
U Pk. Increment i by 1. Go
to step 2.
HOW WE ACTUALLY GO AROUND
COMPUTING A RECTANGLOID DECOMPOSITION?
THE METHOD OF DIVIDE AND LABEL
:-
·
First we divide the cells into smaller cells of equal dimension.
·
And then we lebel the newly created cells according to their intersection
with the C-obstacle region as EMPTY, FULL, or MIXED.
·
This is the basic computation in step 1 and step 3 of the algorithm
proposed above.
2m – Tree
Decomposition :-
·
This is the most widely used method to decompose a rectangloid where m is
the dimension of the configuration space.
·
A 2m tree decomposition
of Ω is a tree of degree 2m (each node has 2m children).
·
The root of the tree is Ω itself.
·
All nodes have 2m children and each are either labeled EMPTY or
FULL or MIXED.
·
Only nodes which are of MIXED types have children.
·
The decomposition is done such that all the children are of equal
dimensions.
·
If m = 2 the tree is called a quadtree. If m = 3 the tree is called an octree.
·
The depth of a node determines the dimension of the corresponding cell
relative to Ω.
·
The height h of the tree
determines the resolution of the decomposition of Ω.Which gives the size
of the smallest cell present in the decomposition tree.
·
For the algorithm we need to specify the initial height h1 of
the decomposition tree. And all the MIXED cells which are at the depths less
than h1 are decomposed at this step.
·
An maximal height hmax og the tree is also specified in order to bound the
iterative process carried out by steps 2 and 3. Every mixed cell whose depth is
equal to hmax is re-lebeled as FULL.
·
In the worst case
the number of leaves in a 2m decomposition tree of height h will be 2mh . Hence it
increases exponentially with dimension of C and the depth of the decomposition.
·
Though
practically the number is not so large as the tree is pruned at every EMPTY or
FULL node.
CELL LEBELLING IN RN :-
·
Assumed that the
robot and the obstacles are both of polygonal type and only the robot is
allowed to translate or we describe the C-obstacle region by the disjunctive
expression called a C – sentence :
V Λ eij
i j
where eij is a C – constraint of the form aij x
+ bij y + cij <= 0. Here each conjunct
Λ eij
represents the C – obstacle of one polygonal
obstacle.
·
A C–sentence Sk is
associated with every MIXED cell k.
·
A cell k is said to be inside the C-constrint eij if all the
points (x,y) Є k satisfy eij. In other words :- if each of its
vertices verifies : aij x + bij y + cij < = 0
·
A cell k is said to be outside the C-constraint eij if all the
points (x,y) Є k contradict eij .In other words :- if
each of its vertices verifies : aij x + bij y + cij >= 0
·
A cell k is said to be cut by the C-constraint eij if the cell
is neither inside nor outside eij .
ALGORITHM FOR LEBELLING OF NEW
CELLS :-
·
Let S is the C-sentence associated with the parent cell of k.
Function
LABEL(k, S) {
For each conjunct Λ
eij Є S do {
For each
C-constraint e Є Λ eij do
{
If k
is inside e then
Λ eij = Λ eij
\ {e}
Else
if k is outside e then
S = S \ { Λ eij}
}
if Λ
eij Є S and Λ eij =φ then {
label k with FULL;
exit(0);
}
if S =
φ then {
label k with EMPTY;
}
else {
label k with MIXED;
associate S with k;
}
}
}
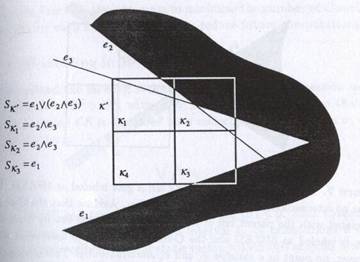
Fig
(1) from the book textbook robot motion planning , describing the labeling
technique as discussed in the algorithm.
This
procedure takes O(n) time to label a cell where n is the number of C-constraints
in the input S.
·
In this procedure we see a new simplified S is associated with newly
labeled MIXED cells. This considerably decreases the computation time for the
labeling of forthcoming cells.
·
Since each C-constraints is treated independently while labeling sometimes
cells may get labeled MIXED even though they are not. It may happen when a cell
k is not outside the C-constraints e1 and e2 although no point of the
cell k is inside both e1 and
e2. however this will no lead to an error as on the next
iteration when that mixed cell will be decomposed each of the cells will be
labeled correctly as EMPTY.
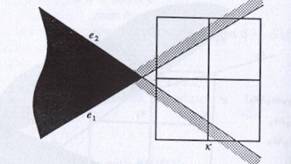
Fig
(2) from the textbook robot motion planning, which shows the case of
conservation described above.
HOW WE GO ABOUT SEARCHING THE
CONNECTIVITY GRAPH?
HIERARCHIAL GRAPH SEARCHING :-
·
This algorithm constructs a hierarchy of CG’s . The CG at the root
corresponds to the first decomposition P1
of Ω . Let us denote the connectivity graph for the cell k as Gk.
·
The graph GΩ is searched for a path connecting qinit to qgoal .
·
If an M-path M1 is found every MIXED cell in M1
is decomposed and searched for a path
that connects qinit to qgoal that connects
appropriately to the rest of the M1.
·
If an E-path is found out then
we are done. Else if we cannot find out an E-path
then we return a failure.
THE ALGORITHM :-
1.
Find out the path M1 using CG G Ω . If M1 is an E-path. We are done.
2.
If M1 is an M-path we construct another path M2 as follows :
We go on considering every successive cell k in M1
starting with the cell that consists of qinit . If k is empty it is added to the new path M2 else if its MIXED ,
it is decomposed into a set Pk
of smaller cells. Let Gk be
the CG associated with Pk
.Gk is then searched for a path
Mk which satisfies the following conditions.
1.
If the cell k is the first cell in M1 then the first cell in Mk
must contain qinit .
2.
If the cell k is the last cell in M1 then the last cell in Mk
must contain qgoal .
3.
If k is not the first cell in M1 then the first cell of Mk
must be adjacent to the last cell of the current M2 .
4.
IF k is not the last cell in M1 then the last cell of Mk
must be adjacent to the subsequent cell in the current path M1.
3.
This Mk is appended to M2 and we carry on the
procedure presented in step 2 until we exhaust all the cells of M1 .
4.
If the new path is an E-path, we can find out a polygonal
path using M2. else we set M1 to M2 and go to step 2.
·
It may be possible that we could not find out a free-path even after we decompose the C-space to the maximum
resolution. In such case we return a failure.
Submitted
by :-
VIVEK
VAIBHAV
Email
id – vivekv@cse.iitk.ac.in