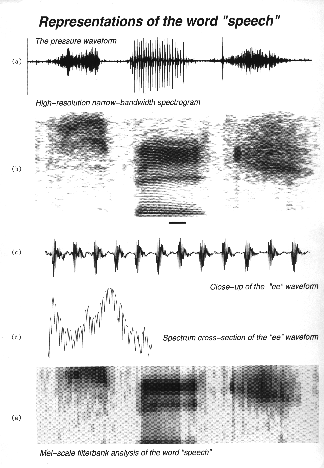
Figure: Examples of representations used in current speech recognizers. (a) time varying waveform of the word speech, showing changes in amplitude (y axis) over time (x axis); (b) speech spectrogram of (a), in terms of frequency (y axis), time (x axis) and amplitude (darkness of the pattern); (c) expanded waveform of the vowel ee (underlined in b); (d) spectrum of the vowel ee, in terms of amplitude (y axis) and frequency (x axis); and (e) Mel-scale spectrogram.
The speech signal is non-stationary. So a time dependent discrete time
fourier transform needs to used. This done by windowing the speech samples
into frames of appropriate size and doing the analysis on each frame. At
this point Hidden Markov Models may be used by using phonemes extracted
from the words.
Back