|
|
Asha Tarachandani and Pooja Nath
IIT Kanpur : April 2000
The purpose of this project is to take English handwritten documents as input, recognize the text and modify the handwriting such that it is a beautified version of the input. Thus the project comprises of two parts - handwriting recognition and beautification.
Handwriting recognition : Lots of work has been done in the field of character recognition but not much for analyzing a complete document. Recognizing the text of a document would be useful in many diverse applications like reading medical prescriptions, bank cheques and other official documents. It will also find uses in detective or police departments in applications like handwriting based person identification, identifying real from forged documents, etc.
Handwriting recognition can be broken into a number of relatively independent modules. After going through several papers and web pages on handwritten word recognition, we thought of various strategies for each of these modules. We then considered the accuracy and efficiency of these strategies independently and as a whole. Also, we came up with a new idea based on feature extraction and relative position matching with the help of directional graphs. Our project is aimed at implementing this idea keeping in mind the strategies which we considered best for an overall accurate, efficient and scalable handwriting recognition software.
Handwriting Beautification : Due to the individual differences in handwriting, a 100% accurate handwriting recognition software has not yet been developed. Human reading ability is dependent on various factors including the knowledge of grammar, context, etc. Hence, it is difficult to build artificial methods to recognize documents as accurately as humans. Also, even a handwriting recognition software with dictionary and context-understanding capabilities cannot guarantee accuracy in recognizing proper nouns. Due to these limitation, we present a scheme for handwriting beautification which modifies the document so that it becomes more presentable while remaining in the individual's handwriting. The output of this scheme can be used by humans to read deformed documents.
The most common reasons for illegibility of English handwritten text are :
The primary aim of this project is to recognize and beautify address
blocks. The Joint Entrance Examination office of IIT, Kanpur receives numerous
applications every year and they have to send the required documents to
all the applicants. For this purpose, the applicants are required to write
their addresses in the address blocks provided. A major problem which the
JEE office is facing now-a-days is that many posted documents do not reach
the applicant due to bad handwriting in the address block. In this project
we aim to recognize and beautify the address blocks to relieve this problem.
Since handling capital letters is much easier than handling small letters,
we limited our domain to capital letters. It is reasonable to make it mandatory
for the applicants to fill in the address block with capital letters. Some
examples are provided in the following section.
Input :
An address block like :

Output:
The text of the address block:
ANIL KUMAR SHUKLA S/O
SHRIRAMBABUSH
Ismail pur (Ameen Gunj)
SoRAM, ALLAHABAD
[Vaidya et al :1999] use a feature-based approach for numeral recognition. They have used a statistical method by assigning weights to each feature and assessing the numerals using these weights. We also use the feature-based approach to recognize the handwritten words. Our approach is different from theirs as words may be written in cursive writing whereas numerals aren't. It is not always possible to break words into characters. Hence we have to use a continuous process of matching the set of features to a database while accounting for the permutations as new features come into view and old ones are discarded. Also, the set of features in the case of alphabets is larger than that in the case of numerals.
[Nicchiotti/Scagliola:1999] have shown some good examples of normalization by removing unwanted variations in cursive handwriting using estimation and compensation of reference lines and slant angle. In the preprocessing of documents for the purpose of recognition and beautification, normalization is an important step to facilitate feature extraction.
[Spitz:1998] use character shape coding process for typed word recognition. They have a small dictionary to which all the words in the document belong. After scanning the words, they are classified on the basis of the regions that they occupy (extending above middle-line, extending below bottom-line or completely between the two). This narrows down the range of possibilities for the word which is then matched against all these possibilities. We had considered this approach but it would have been highly inefficient in our case which is more general as ours is not restricted to a small fraction of a dictionary nor is it restricted to typed documents where the characters are easily distinguishable.
Given an address block in pgm format, this project proceeds in the following steps to generate the desired output.



Partial thinning on the example.

[Datta/Parui] algorithm applied on partially thinned image.
![]()
Thinned and slant corrected image
As the results depends heavily on efficiency of this step, special care is taken to make sure that the features detected are correct. For this purpose, we did a lot of experimentation by playing with the order of feature detecting steps and with the values of the thresholds involved.
For example, the procedure that we followed for detecting a vertical line was by checking if there is an almost vertical line of black pixels whose length is greater than some threshold. The threshold that we earlier used was 5/8 of the height of the line that is being scanned. It gave poor results in cases where a name is written with the first character much bigger than the rest. Thus, we decided that the threshold should be 5/8 of the height of the character being scanned and not the line. This improved feature detection tremendously.
Also, we observed that if we tried to detect slant lines after vertical lines, some of the vertical lines were also being mistaken for slants. To overcome this problem, we improved on the threshold for slant lines as well as marked the pixels in the vertical lines as detected so that they are not detected again.
Features: These are a predefined set of elementary parts which, when combined in various fashions, constitute all the characters. Some examples of features are vertical line, horizontal line, left curve, right curve, etc. Each feature has an associated set of x and y co-ordinates w.r.t. the figure.
Characters: Depending on the relative position of features in it, a character can be viewed as a Directional Graph of Features called feature-graphs. For example the division of the letter a into features and the corresponding directional graph is as follows :
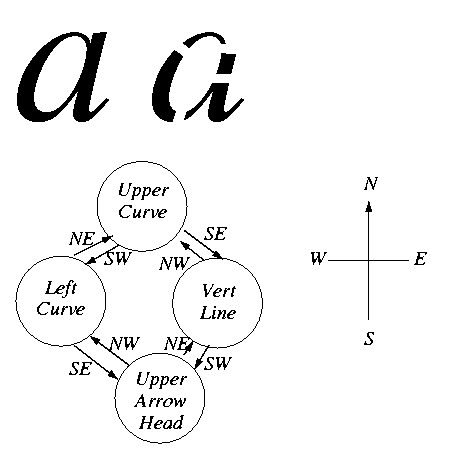
Thus, we create a database for handwriting recognition which consists
of a set of feature-graphs for each of the 26 English alphabets. Further,
some characters like a, f, g, etc. may be written in more than one style.
This is taken care of by maintaining graphs for all such styles.
| Original Image | |
| Image after thinning | |
| Image after slant correction | |
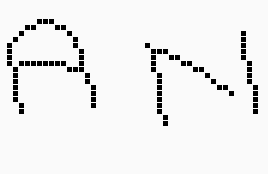 |
Partial magnified view of the above thinned image
Before slant correction |
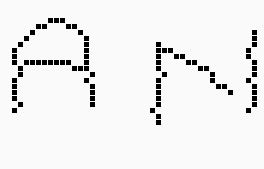 |
After slant correction |
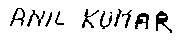 |
Original Image |
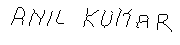 |
Image after thinning |
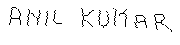 |
Image after slant correction |
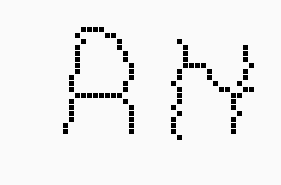 |
Thinning after slant correction. |
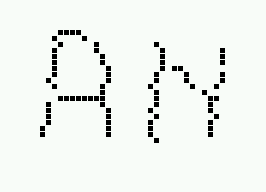 |
Slant Correction after thinning. |
 |
Original Image |
 |
Image after partial thinning |
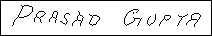 |
Image after thinning |
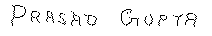 |
Image after slant correction |
Some preliminary results on feature detection
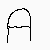 |
long horizontal feature at : i = 18
j = 12 length=23
short horizontal feature at : i = 0 j = 15 length=11 long vertical feature : j =18 i =22 length=29 short vertical feature at : i =21 j =1 length=27 |
character 0 : A / |
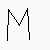 |
long vertical feature
: j =16 i =0 length=32
long vertical feature : j =18 i =21 length=27 rt dia feature at : i =9 j =6 height =17 width =11 left dia feature at : i =8 j =15 height=18 width=9 |
character 0 : IVI / M / |
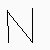 |
long vertical feature
: j =17 i =24 length=35
long vertical feature : j =18 i =0 length=33 rt dia feature at : i =17 j =11 height =27 width =22 |
character 0 : IV / N / |
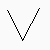 |
rt dia feature at
: i =17 j =8
height =31 width =16
left dia feature at : i =16 j =23 height=33 width=17 |
character 0 : V / |
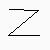 |
long horizontal feature at : i = 26
j = 15 length=32
long horizontal feature at : i = 0 j = 15 length=30 left dia feature at : i =13 j =15 height=24 width=28 |
character 0 : Z / |
| Features
Horizontal - 9
|
character 0 : II / CI
/ II / A /
character 1 : L / character 2 : L / character 3 : III / CII / III / AI / DI / OI / character 4 : LI / H / character 5 : _ / |
|
| Features
Horizontal - 12
|
character 0 : IV / N
/
character 1 : E / character 2 : E / character 3 : L / character 4 : II / CI / II / A / character 5 : J / |
|
| Features
Horizontal - 6
|
character 0 : LI / U
/
character 1 : T / character 2 : T / character 3 : II / A / character 4 : L / |
|
| Features
Horizontal - 5
|
character 0 : A /
character 1 : LT / character 2 : I / character 3 : T / |
|
| Features
Horizontal - 6
|
character 0 : IJI / A
/
character 1 : I / character 2 : ICI / II / A / |
| character 0 : A /
character 1 : T / character 2 : LI / character 3 : LI / U / |
||
| character 0 : FI /
character 1 : L / character 2 : L / character 3 : FII / AI / character 4 : LI / H / character 5 : _ / |
||
| character 0 : IV / N /
character 1 : E / character 2 : E / character 3 : L / character 4 : FI / A / character 5 : J / |
||
| character 0 : LI / U /
character 1 : T / character 2 : T / character 3 : FI / A / character 4 : L / |
||
| character 0 : A /
character 1 : TT / character 2 : I / character 3 : T / |
||
| character 0 : _ /
character 1 : I / character 2 : IFI / A / |
||
| character 0 : FI / A /
character 1 : LI / U / character 2 : V / character 3 : L / character 4 : I / character 5 : Z / character 6 : I / |
||
An extension to this project could be to use weights and spell checking in Continuous Matching in step 9. The algorithm of continuous matching with weights is described below.
Continuous Matching (with weights): The handwritten word
from the document is broken up into the predefined features. A continuous
process of determining the relative positions of these features and comparing
them with the database of feature-graphs goes on until a match is obtained.A
weight is attached to the character depending on the extent to which it
matches the set of features. It should be noted here that the past history
is not completely erased in the continuous process thus obtaining more
than one possible match for the word. In this way, mistakes like d
being mistaken for a c followed by an l can be avoided.
The weight of each word is the sum of the weights of its characters.
These words are spell-checked and the correct one with the highest weight
is chosen.
@Article{Spitz:1998,
author = { Spitz, L. },
title = { Shape-based word
recognition},
journal = { International Journal on Document
Analysis and Recognition },
year = { 1998},
keywords = { WORD RECOGNITION, SHAPE CODES },
institution ={ Document Recognition Technologies Inc. },
month = { October },
pages = { 178 -190 },
annote = { This paper uses an interesting
method to recognize typed documents by recognizing the shape of individual
words. The characters are classified as x (those with no points above the
middle line) and non-x type. The document can contain words only from a
limited dictionary. Hence, once the word shape is built up from character
shapes, the word is identified by template matching with all the possible
words in the dictionary. For example, a word of the shape AxAA (where A
denotes non-x and x denotes x type) could only match words like Bell, Both,
Bull etc.
}}
@InProceedings{Vaidya:1999,
author = { Vaidya, V. and Deshpande, G.
and Shirole,B.},
title = { Statistical Approach to
Feature Extraction for Numeral Recognition from Degraded Documents},
booktitle = { International Conference on Document Analysis
and Recognition}
year = { 1999},
keywords = { FEATURE EXTRACTION, NUMERAL RECOGNITION},
institution ={ Siemens Information Systems Limited },
month = { August },
pages = { 273-276 },
annote = {This paper talks about numeral
recognition which is a very important issue for reading pin codes and bank
cheques. It divides the numeral to be recognized into features like loops,
horizontal lines etc. and then compares them with the standards stored
in the database. It assigns some weights to the numerals depending on the
visibility of the feature and matching between the features of the handwritten
numeral and the standard numeral in the database.
}}
@Article{Datta/Parui:1994
author = { Datta, A. and Parui, S. K. },
title = { A Robust Parallel Thinning
Algorithm for Binary Images },
booktitle = { Pattern Recognition },
Volume = { 27 }
Number = { 9 }
year = { 1994 },
keywords = { BINARY OBJECT, ITERATIVE THINNING, SKELETON,
MEDIAL AXIS, ROBUSTNESS },
institution ={ Indian Statistical Institute },
month = { March },
pages = { 1181-1192 },
annote = { The aim of this paper is to
determine the skeleton of a binary image. For this purpose, the unnecessary
black pixels are removed from the image iteratively. This is done by considering
the black pixels one by one and removing them if (a) It has a black and
a white pixel neighbour along a given straight line, (b) Its removal leaves
the connectivity of the black pixels unchanged, and (c) It is not the last
black pixel in a linear chain of black pixels.
This paper presents some excellent results. For example, the skeleton
of a triangle comes out to be an inverted T. Since the algorithm preserves
connectivity and does not remove end-pixels, it is rpbust and is able to
provide good results for many arbitrary shapes.
}}
@InProceedings{Ding:1999
author = { Ding, Y. and Kimura, F. and
Miyake, Y. and Shridhar, M. },
title = { Evaluation and Improvement
of Slant Estimation for Handwritten Words },
booktitle = { International Conference on Document Analysis
and Recognition },
year = { 1999 },
keywords = { SLANT ESTIMATION, HANDWRITING },
institution ={ Mie University and University of Michigan-Dearbon
},
month = { August },
pages = { 753-756 },
annote = { This paper provides a simple
iterative algorithm for estimating the slant of a word. They are able to
reach some very good results. }
}
@InProceedings{Madhavan:1999
author = { Madhavan, s. and Kim, G. and
Govindraju, V.},
title = { Chaincode contour Processing
for Handwritten Word Recognition },
booktitle = {IEEE Transactions on Pattern Analysis and Machine
Intelligence },
year = { 1999 },
Volume = { 21 },
Number = { 9 },
keywords = { HANDWRITING RECOGNITION, WORD RECOGNITION,
CONTOUR PROCESSING, CHAINCODE },
institution ={ IEEE Computer Society },
month = { September },
pages = { 928-932 },
annote = { According to this paper, the
first step to word recognition is edge detection after which a counter-clockwise
scan of the contour thus generated leads to identification of the characters.
Using this counter-clockwise scan, the authors try to determine the features
in the word.
}}
@InProceedings{Morita:1999
author = { Morita, M. and Facon, J. and
Bortolozzi, F.},
title = { Mathematical Morphology
and Weighted Least Squares to Correct Handwriting Baseline Skew },
booktitle = { International Conference on Document Analysis
and Recognition }
year = { 1999},
keywords = { BASELINE SKEW, MORPHOLOGY },
institution ={ PUCPR and UFPR and ETs },
month = { August },
pages = { 430-433 },
annote = { This paper talks of an approach
to correct baseline skew specifically tailored to bank cheques. Correcting
baseline skew is an important step in preprocessing to reduce the variation
in handwritten texts. It uses a statistical approach with weighted least
squares method for this purpose.
}}
@InProceedings{Lee/Gomes:1999
author = { Lee, L. and Gomes, N.},
title = { Automatic Classification
of Deformed Handwritten Numeral Characters },
booktitle = { International Conference on Document Analysis
and Recognition }
year = { 1999 },
keywords = { HANDWRITTEN, NUMERAL },
institution ={ State Universitry of Campinas, Brazil },
month = { August },
pages = { 269-272 },
annote = { This paper talks of classifying
handwritten numerals based on features. If classification is not possible
in first stage, neural networks are applied. They claim that their method
gives correct output in 92.4% cases. Such softwares are very useful in
reading bank cheques.
}}
Acknowledgement:
We would like to acknowledge that the images used in this report were
provided by JEE office of IIT, Kanpur.
This report was prepared by Asha Tarachandani and Pooja Nath as a part of the project component in the Course on Artificial Intelligence in Engineering in the JAN semester of 2000 . (Instructor : Amitabha Mukerjee )
[ COURSE WEB PAGE ] [ COURSE PROJECTS 2000 (local CC users) ]