Given a collection of objects let us say we have the task to classify the objects into two groups based on some feature(s). For example, let us say given some pens and pencils of different types and makes, we can easily seperate them into two classes, namely pens and pencils. This seemingly trivial task, if we take a moment would seem to involve a lot of underlying computation. The question to ask would be what is our basis for classification? And how perhaps might we incorporate the principle to allow for efficient classification by 'intelligent algorithms'.
In simple terms instead of having hard coded algorithms to do specific tasks, flexibility is introduced by having an algorithm "learn". This is usually called the 'programming by example' paradigm. Which is to say, instead of us giving the algorithm on which to base its classifying principles we let the machine itself come up with its own 'algorithm' based on examples that we provide. This would mean that we would give it, lets say, hundred instances each of different kinds of pens and pencils, labelled correctly, whose features it can study.(This forms the Training Dataset, the 'examples' from above). And now the machine comes up with its own prediction rule based on which a new example (unlabelled) would be classified as a pen or pencil!
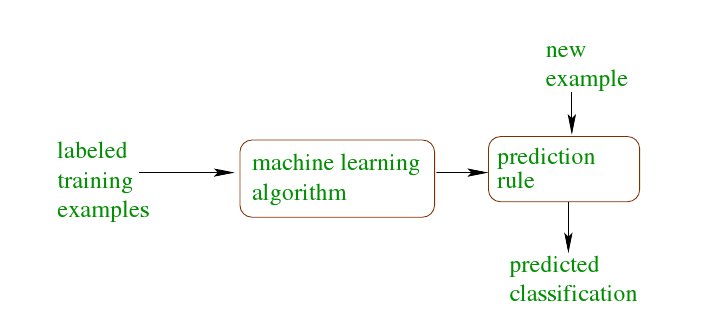 Ref: Theoretical Machine Learning - Rob Schapire, Princeton Course Archive
Ref: Theoretical Machine Learning - Rob Schapire, Princeton Course Archive
Now we mainly have two kinds of Machine Learning Algorithms: Supervised and Unsupervised. This is akin to the examples being provided alongwith their correct labels, in case of supervised. And in the case of unsupervised learning the algorithm divides the input dataset into subsets and clusters them basing it on its own similarity computation. Here there are no labels given with the input, rather the data is divided by the algorithm itself with what seems to it as a reasonable set of classes.
Binary Classification would generally fall into the domain of Supervised Learning since the training dataset is labelled. And as the name suggests it is simply a special case in which there are only two classes.
Some typical examples include:
Now there are various paradigms that are used for learning binary classifiers which include:
Support vector machines (SVMs) are a set of supervised learning methods which learn from the dataset and used for classification. Given a set of training examples, each marked as belonging to one of two classes, an SVM algorithm builds a model that predicts whether a new example falls into one class or the other. Simply speaking, we can think of an SVM model as representing the examples as points in space, mapped so that each of the examples of the separate classes are divided by a gap that is as wide as possible. New examples are then mapped into the same space and classified to belong to the class based on which side of the gap they fall on.
More formally it constructs a hyperplane or set of hyperplanes in a high or infinite dimensional space, which can then be used for classification as described above. Now if we view a data point as an n dimensional vector, we want to separate the points by an n-1 dimensional hyperplane.Of the many hyperplanes that might classify the data, One reasonable choice is such that the distance from the hyperplane to the nearest data point on each side is maximized. This is what is called a maximum margin hyperplane.
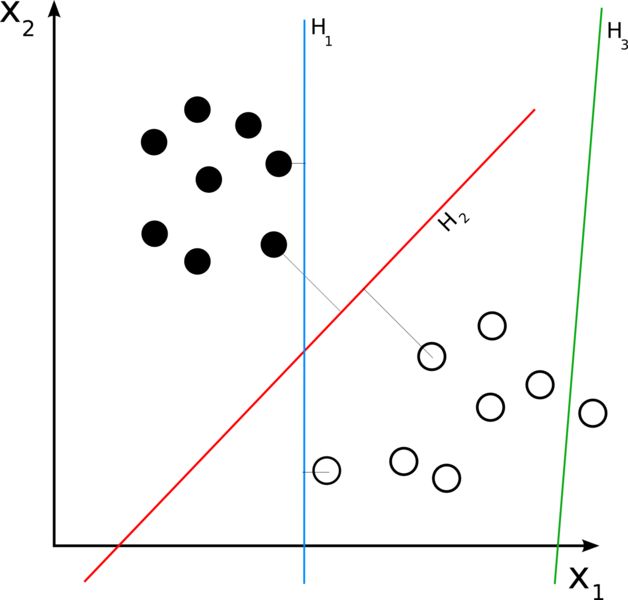 Ref: wikimedia
Ref: wikimedia
We worked on a project to do Sentiment Classification, which I hpoe would illuminate better the problem of Binary Classification! Sentiment Classification involves classifying a review (say IMDB Movie Review) into whether it expresses a positive or a negative sentiment of the reviewer. In this basically a dataset of two thousand reviews consisting of one thousand reviews annotated positive and one thousand reviews annotated negative was considered. Now the task is to classify a novel review based on its sentiment.
How this was worked was that using various Data Mining Software, each of the review of the dataset was converted into a document vector, akin to a 'bag of words' paradigm( since only the presence or absence of a word was considered, not the context). Thus the words of the documents were stemmed and and Dataset Vector was constructed consisting of all of the unique words appearing in the Dataset. Thus each Data Point was now a vector, where each dimension corresponded to unique word. The occurrence of words was set as either binary or using TFIDF. Now an SVM classifier was used which trained on the dataset thereby mapping the vectors and obtaining a hyperplane for seperation. A good accuracy of about ~83% was obtained using this classifier!
Thus we hope that with this illustration the wide array of problems that can be tackled using Machine Learning Algorithms is highlighted. Also we would like to stress upon the importance of Learning in the context of AI. We would not consider a system to be truly intelligent if it were incapable of learning since learning seems to be at the core of intelligence!